
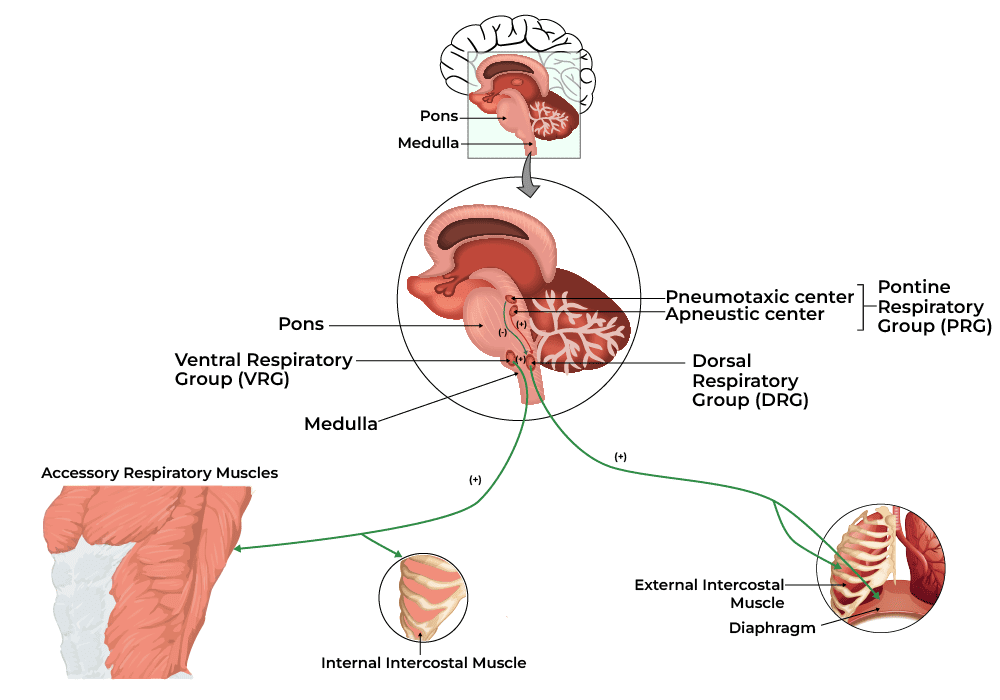
Control of Respiration (Neural and Chemical Regulation)
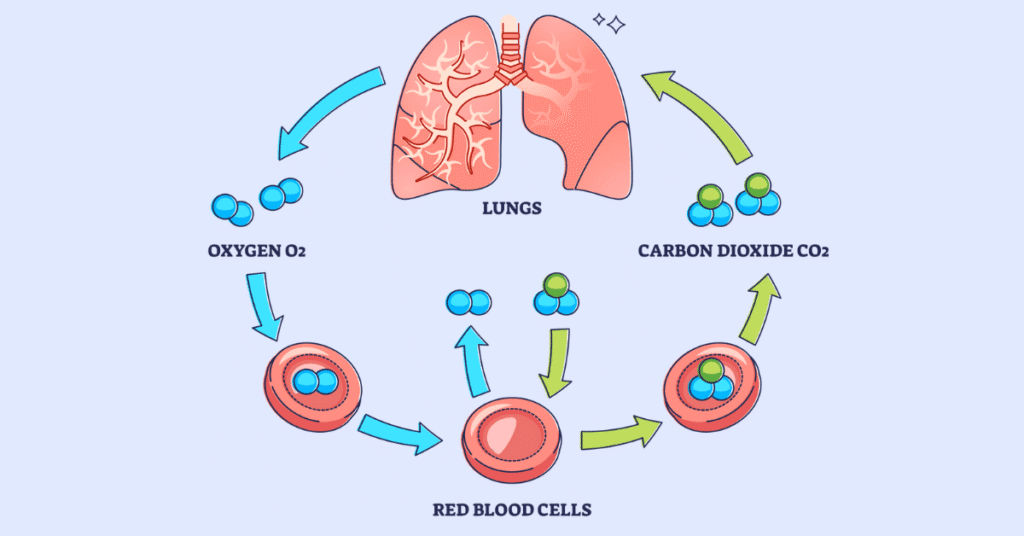
Gas Exchange and Transport
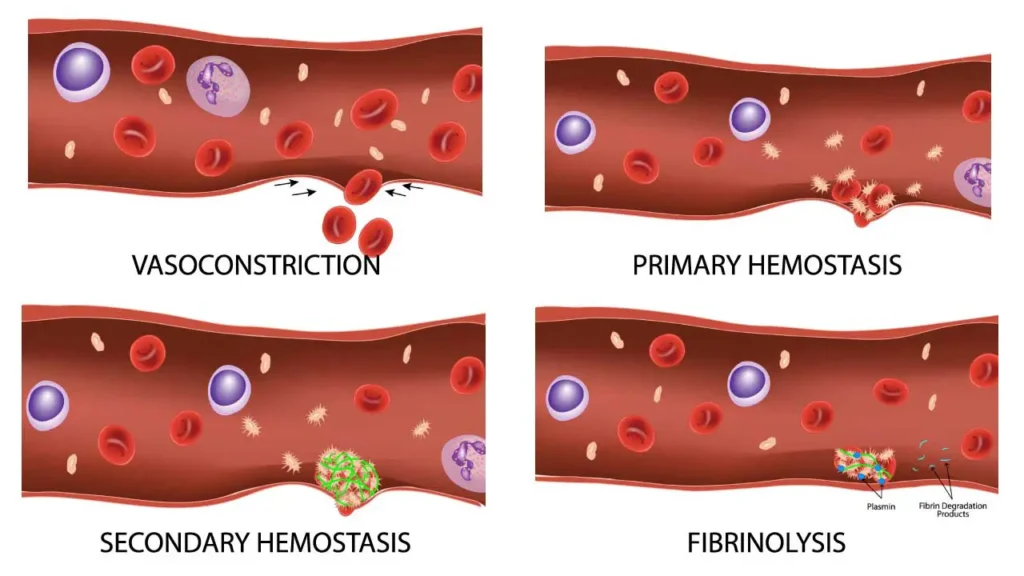
Platelets and Hemostasis
Platelets and Hemostasis
By the conclusion of this exhaustive guide, you will be deeply conversant with:
- The delicate physiological balance of Hemostasis (preventing hemorrhage vs. preventing thrombosis).
- The morphology, lifecycle, and critical functions of Platelets in Primary Hemostasis.
- The enzymatic cascade of Secondary Hemostasis, mastering both the Traditional and Cell-Based models.
- The body's natural Anticoagulant and Fibrinolytic systems.
- The interpretation of Hemostasis Laboratory Tests (PT, aPTT, INR, D-Dimer).
- The pathophysiology and clinical presentation of Bleeding and Thrombotic Disorders.
I. Introduction to Hemostasis
Hemostasis is the highly regulated, dynamic physiological process that halts bleeding at the site of a vascular injury while simultaneously maintaining normal, fluid blood flow elsewhere in the circulatory system. It represents an exquisite biological balancing act.
If the hemostatic balance tips in one direction, hemorrhage (excessive, life-threatening bleeding) occurs. If it tips in the opposite direction, thrombosis (inappropriate, dangerous blood clotting inside intact vessels) occurs, leading to conditions like myocardial infarctions (heart attacks) and ischemic strokes.
The process involves continuous interactions between three primary components:
- The Blood Vessel Wall (Endothelium): Healthy endothelium prevents clotting; injured endothelium strongly initiates it.
- Platelets (Thrombocytes): Cellular fragments that create the initial physical plug.
- The Coagulation Cascade: Plasma proteins that form a biological "cement" to solidify the plug.
II. Platelets
Platelets (thrombocytes) are small, anucleated (lacking a nucleus) cell fragments that play the central role in Primary Hemostasis—the rapid formation of an initial, temporary platelet plug at the site of vascular injury.
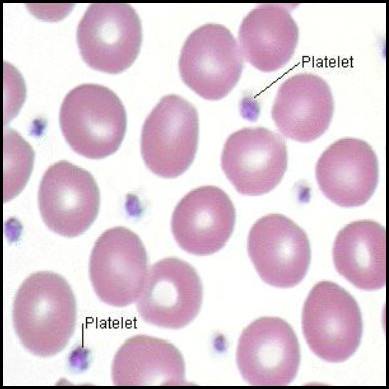
1. Morphology and Physical Traits
- Size and Shape: They are tiny, measuring only 2-4 µm in diameter. When resting/inactive, they are discoid (lens-shaped) to flow smoothly through capillaries. Upon activation, they undergo a massive conformational change, becoming spherical and shooting out long, spiky pseudopods (finger-like projections) to enhance their surface area and stickiness.
- Anucleated Nature: Because they lack a nucleus, platelets cannot transcribe DNA or synthesize new proteins. This is clinically vital: if a drug (like Aspirin) permanently disables a platelet's enzyme, that platelet is disabled for the rest of its life because it cannot build replacement enzymes.
- Lifespan: Highly limited, living only 7 to 10 days in circulation before being destroyed by macrophages in the spleen and liver.
2. The Platelet Membrane Receptors
The platelet membrane is studded with critical glycoprotein (GP) receptors that act as biological velcro, allowing the platelet to stick to injured tissue and to other platelets.
- GP Ib/IX/V Complex: Binds to von Willebrand Factor (vWF), which coats the exposed collagen of a damaged blood vessel.
- GP Ia/IIa Complex: Binds directly to exposed subendothelial Collagen.
- GP IIb/IIIa Complex: The most abundant receptor. When activated, it binds to Fibrinogen, which acts as a bridge to connect multiple platelets together. (Clinical Example: Drugs like Abciximab or Tirofiban are GP IIb/IIIa inhibitors used during heart procedures to prevent platelets from linking together).
The Cytoplasmic Payload
The platelet cytoplasm contains highly specialized granules that release chemicals to amplify the clotting response.
- Alpha-granules (The Proteins): Contain large proteins essential for adhesion and healing. Includes Fibrinogen, von Willebrand factor (vWF), Platelet factor 4 (PF4), Platelet-Derived Growth Factor (PDGF), and P-selectin.
- Dense/Delta-granules (The Activators): Contain smaller, non-protein molecules. Mnemonic: SAC. Serotonin (causes vasoconstriction), ADP/ATP (powerful platelet activators), and Calcium (essential for the coagulation cascade).
- Lysosomes: Contain hydrolytic enzymes for digesting extracellular material.
3. Formation of Platelets (Thrombopoiesis)
Platelet production occurs entirely in the bone marrow and is heavily regulated by a hormone called Thrombopoietin (TPO), which is primarily synthesized in the liver.
- Origin: Hematopoietic Stem Cells (HSCs) differentiate into the Common Myeloid Progenitor (CMP).
- Megakaryoblast Stage: The progenitor cell undergoes endoreduplication (DNA replicates repeatedly, but the cell never divides). The cell becomes massively polyploid (containing up to 64 copies of DNA).
- Megakaryocyte Stage: The resulting cell is the largest in the bone marrow (up to 100 µm) with a bizarre, highly lobulated nucleus.
- Platelet Release: The megakaryocyte extends long, ribbon-like "proplatelets" directly into the bone marrow sinusoidal capillaries. The sheer physical force of flowing blood fragments these extensions into thousands of individual platelets (about 1,000-3,000 per megakaryocyte).
TPO Regulation (Negative Feedback): TPO constantly stimulates megakaryocytes. Platelets floating in the blood have receptors that bind to and destroy TPO. Therefore, if platelet counts are high, all TPO is absorbed, and production slows down. If platelet counts drop (e.g., severe bleeding), free TPO levels rise, stimulating the marrow to produce more.
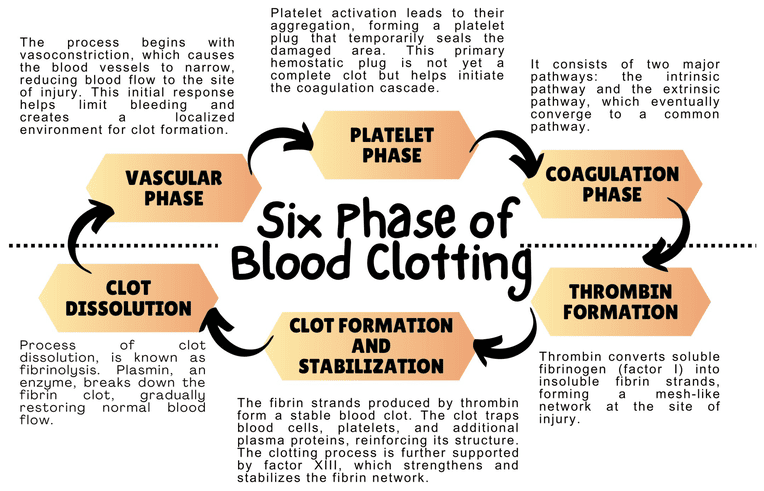
III. The Steps of Primary Hemostasis
When a blood vessel is damaged, exposing the underlying collagen and connective tissue, platelets execute a rapid, four-step response to plug the hole.
Step 1: Adhesion
- Vascular injury exposes subendothelial collagen.
- Endothelial cells release von Willebrand factor (vWF), which unfurls and sticks to the collagen.
- Platelets utilize their GP Ib receptors to bind to the vWF. Think of vWF as a highly adhesive glue connecting the damaged wall to the platelet. Direct binding to collagen also occurs via GP Ia/IIa.
Step 2: Activation
- Once tethered to the wall, platelets undergo a massive shape change (from smooth discs to spiky spheres) and "degranulate" (dump their alpha and dense granules into the blood).
- Key Molecules Released/Synthesized:
- ADP: A potent activator that calls thousands of other platelets to the area.
- Thromboxane A2 (TxA2): Synthesized rapidly inside the platelet via the COX-1 enzyme pathway. TxA2 is a violent vasoconstrictor and powerful platelet aggregator.
- Serotonin: Causes further vascular spasm to reduce blood loss.
Clinical Pharmacology: Aspirin Mechanism
Aspirin works as a blood thinner by irreversibly inhibiting the Cyclooxygenase-1 (COX-1) enzyme inside platelets. Without COX-1, the platelet cannot synthesize Thromboxane A2 (TxA2). Without TxA2, platelet activation and aggregation are severely crippled. Because platelets lack a nucleus, they cannot build new COX-1; therefore, the platelet is permanently disabled for its entire 7-10 day lifespan. This is why low-dose aspirin is given to prevent heart attacks.
Step 3: Aggregation
- Activation causes the platelet's GP IIb/IIIa receptors to change shape and become highly receptive.
- Plasma Fibrinogen binds to the GP IIb/IIIa receptors on adjacent platelets, acting as a molecular bridge.
- Thousands of platelets link together, forming the initial Primary Hemostatic Plug.
Step 4: Procoagulant Activity
- Activated platelets flip their cell membranes inside out, exposing a negatively charged lipid called phosphatidylserine on their outer surface.
- This negatively charged surface acts as the physical "workbench" where the enzymes of the Coagulation Cascade will assemble and function.
IV. Secondary Hemostasis (The Coagulation Cascade)
While the primary platelet plug is an excellent immediate seal, it is weak and friable. It cannot withstand the high-pressure pumping of arterial blood. Secondary Hemostasis involves a series of enzymatic reactions in the plasma that ultimately generate Fibrin—a tough, insoluble protein mesh that wraps around and solidifies the platelet plug.
We analyze this cascade using two models: the Traditional Model (used for understanding lab tests) and the Cell-Based Model (how it actually happens in the human body).
A. The Traditional Model (The Y-Shaped Pathway)
This model divides coagulation into the Extrinsic, Intrinsic, and Common pathways.
The "Initiator"
Activated rapidly by external trauma to the blood vessel.
- Step 1: Injury exposes Tissue Factor (TF), a protein normally hidden on smooth muscle cells and fibroblasts beneath the endothelium.
- Step 2: Circulating Factor VII binds to TF to form the TF-VIIa complex.
- Step 3: This complex directly activates Factor X (to Xa) and Factor IX (to IXa).
The "Amplifier"
Activated when blood comes into contact with negatively charged surfaces (like exposed collagen or glass in a test tube).
- Step 1: Factor XII is activated to XIIa.
- Step 2: XIIa activates Factor XI to XIa.
- Step 3: XIa activates Factor IX to IXa.
- Step 4 (The Tenase Complex): Factor IXa combines with cofactor VIIIa (and Calcium) on the platelet surface. This complex aggressively activates Factor X to Xa.
3. The Common Pathway
Both the Extrinsic and Intrinsic pathways converge at the activation of Factor X.
- Step 1 (The Prothrombinase Complex): Activated Factor X (Xa) combines with cofactor Va (and Calcium) on the platelet phospholipid surface.
- Step 2 (The Central Event): The Prothrombinase Complex takes Prothrombin (Factor II) and cleaves it into the highly active, powerful enzyme Thrombin (Factor IIa).
- Step 3 (The Role of Thrombin): Thrombin is the master regulator. It does multiple things simultaneously:
- Converts soluble Fibrinogen (Factor I) into insoluble Fibrin monomers.
- Activates Factor XIII (the cross-linker).
- Feeds back to massively activate Factors V, VIII, and XI (creating a violent positive feedback loop).
- Strongly activates more platelets.
- Step 4 (Stabilization): Fibrin monomers link together into a weak polymer. Finally, Factor XIIIa (a transglutaminase enzyme) acts like biological sewing thread, covalently cross-linking the fibrin strands into a highly stable, indestructible mesh.
B. The Cell-Based Model of Coagulation
In living humans, coagulation doesn't happen in isolated pathways; it happens directly on the surfaces of cells in three overlapping phases:
- Initiation Phase: Occurs on Tissue Factor-bearing cells outside the vessel. TF binds VIIa, activating small amounts of X and IX. This generates a tiny "Thrombin Spurt," which is not enough to clot blood, but enough to sound the alarm.
- Amplification Phase: The "Thrombin Spurt" activates local platelets and circulating cofactors (V, VIII, XI), priming the environment for a massive reaction.
- Propagation Phase: Occurs exclusively on the surface of activated platelets. The Tenase complex (IXa/VIIIa) and Prothrombinase complex (Xa/Va) assemble on the platelets, generating a massive "Thrombin Burst." This burst rapidly converts fibrinogen to a robust fibrin clot.
Vitamin K and Calcium
- Vitamin K-Dependent Factors: Factors II, VII, IX, X, Protein C, and Protein S all require Vitamin K for synthesis in the liver. Vitamin K adds a carboxyl group to these proteins, allowing them to bind to Calcium.
Pharmacology Note: Warfarin (Coumadin) is an oral blood thinner that poisons the Vitamin K recycling enzyme in the liver, shutting down the production of these factors. - Calcium (Factor IV): Calcium acts as the bridge connecting the coagulation factors to the negatively charged surface of the activated platelet. Without Calcium, blood cannot clot. (This is why blood donation bags contain EDTA or Citrate—chemicals that bind all the Calcium, keeping the blood liquid in the bag).
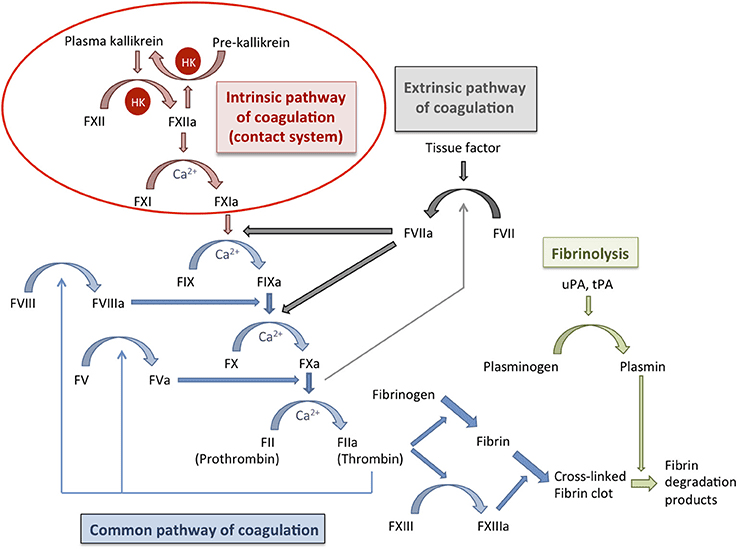
V. Regulation of Clotting and Fibrinolysis
Hemostasis requires aggressive regulation. If the coagulation cascade was left unchecked, a tiny cut on your finger would cause your entire circulatory system to clot solid. The body uses anticoagulation systems to restrict the clot strictly to the site of injury, and Fibrinolysis to dissolve the clot once healing is complete.
A. Natural Anticoagulation Systems
Mechanism: A major plasma protein that chemically binds to and destroys several activated factors, primarily Thrombin (IIa) and Factor Xa.
Pharmacological Enhancement: By itself, Antithrombin acts slowly. However, when it binds to Heparin (a drug) or heparan sulfate (found naturally on healthy blood vessels), its action is accelerated 1,000-fold. This is exactly how Heparin acts as a rapid IV blood thinner in hospitals.
Mechanism: When healthy, uninjured endothelium encounters stray Thrombin, a receptor called Thrombomodulin captures the Thrombin. This complex activates Protein C into Activated Protein C (APC).
Action: APC, assisted by Protein S, acts as a biological assassin, seeking out and destroying the essential cofactors Va and VIIIa. This brutally shuts down the cascade. (Pathology Note: A genetic mutation called Factor V Leiden makes Factor V immune to destruction by APC, leading to severe hypercoagulability).
Mechanism: Directly blocks the Extrinsic pathway initiator. TFPI binds to and permanently inactivates the TF-VIIa-Xa complex, turning off the "initiator" tap.
B. Clot Dissolution (Fibrinolysis)
Once the injured vessel is repaired with new endothelial cells, the old fibrin scab must be dissolved to restore normal blood flow.
- The Key Enzyme - Plasmin: A powerful serine protease that chops up fibrin and fibrinogen, dismantling the clot.
- Activation: Plasmin floats in the blood in an inactive form called Plasminogen. It is converted into active Plasmin by Tissue Plasminogen Activator (t-PA) (released slowly by healed endothelial cells) or Urokinase (u-PA).
- Inhibitors of Fibrinolysis: The body uses PAI-1 (Plasminogen Activator Inhibitor-1) and Alpha-2-antiplasmin to ensure clots don't dissolve too early, which would cause re-bleeding.
- Breakdown Products: When Plasmin destroys cross-linked fibrin, it leaves behind distinctive trash molecules in the blood called Fibrin Degradation Products (FDPs), the most famous of which is the D-Dimer.
Clinical Application: "Clot Busters" (Thrombolytics)
If a patient arrives at the Emergency Department having an ischemic stroke (a clot blocking blood to the brain), doctors will inject synthetic recombinant t-PA (Alteplase). This drug forces massive, systemic conversion of Plasminogen to Plasmin, aggressively dissolving the clot in the brain and restoring blood flow. Because it destroys all clots, the major side effect is severe bleeding.
VI. Laboratory Tests for Hemostasis
Laboratory tests are vital for distinguishing whether a patient has a primary platelet defect or a secondary coagulation factor defect.
| Test Name | What it Measures | Normal Range | Clinical Significance & Abnormalities |
|---|---|---|---|
| Platelet Count | Total number of platelets in the blood. | 150,000 - 450,000 / µL | Low (Thrombocytopenia): Risk of mucosal bleeding. High (Thrombocytosis): Risk of thrombosis. |
| PFA-100 / Aggregometry | Platelet *function* (adhesion and aggregation). | Depends on assay | If platelet count is normal but the patient is bleeding, PFA-100 checks if the platelets are "lazy" or broken (e.g., von Willebrand Disease, Aspirin toxicity). |
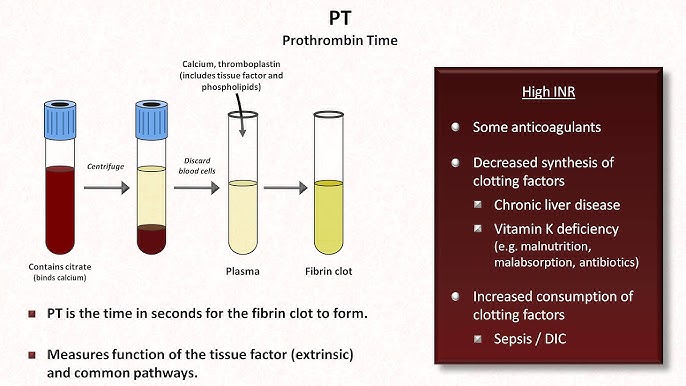
| Prothrombin Time (PT) & INR | Measures the Extrinsic and Common Pathways. | PT: 10-14 seconds INR: 0.8 - 1.2 |
Mnemonic: "PeT" (PT = Extrinsic). Prolonged by deficiencies in VII, X, V, II, or Fibrinogen. Heavily used to monitor Warfarin therapy and liver failure. |
| Activated Partial Thromboplastin Time (aPTT) | Measures the Intrinsic and Common Pathways. | 25 - 35 seconds | Prolonged by deficiencies in XII, XI, IX, VIII (Hemophilia). Heavily used to monitor Heparin therapy. |
| D-Dimer | Measures the presence of degraded, cross-linked fibrin. | < 500 ng/mL | Highly Sensitive, Low Specificity. If elevated, it means the body is making and breaking clots (DVT, PE, DIC). If negative, you can confidently rule out a major blood clot. |
VII. Common Disorders of Hemostasis
Hemostasis disorders generally present in specific patterns. Primary disorders cause superficial bleeding (skin, mucous membranes), while secondary disorders cause deep tissue bleeding.
A. Primary Hemostasis Disorders (Platelet / Vessel Wall Defects)
Symptoms: Mucocutaneous bleeding (nosebleeds/epistaxis, bleeding gums, heavy menses), Petechiae (tiny pinpoint skin hemorrhages), and Purpura (larger purple skin bruises).
- Thrombocytopenia (Low Platelets):
- Decreased Production: Bone marrow failure, leukemia, chemotherapy, B12/folate deficiency.
- Increased Destruction: Immune Thrombocytopenic Purpura (ITP - antibodies destroy platelets), Thrombotic Thrombocytopenic Purpura (TTP - micro-clots shred platelets).
- Sequestration: Splenomegaly (an enlarged spleen acts as a sponge, trapping platelets).
- Platelet Function Disorders:
- Inherited: Glanzmann's thrombasthenia (missing GP IIb/IIIa, cannot aggregate), Bernard-Soulier syndrome (missing GP Ib, cannot adhere to vWF).
- Acquired: Aspirin/NSAID use, Uremia (severe kidney failure poisons platelets).
- Von Willebrand Disease (vWD): The most common inherited bleeding disorder. Patients lack functional vWF. Without vWF, platelets cannot stick to the wall (primary defect). Furthermore, vWF normally protects Factor VIII in the blood; without it, Factor VIII degrades rapidly (secondary defect).
Labs: Normal platelet count, abnormal PFA-100, prolonged aPTT (due to low Factor VIII).
B. Secondary Hemostasis Disorders (Coagulation Factor Defects)
Symptoms: Deep tissue bleeding, Hemarthroses (massive bleeding directly into joints causing swelling and pain), and large deep muscle hematomas.
- Hemophilia A (Factor VIII def.) & Hemophilia B (Factor IX def.): X-linked recessive genetic disorders almost exclusively affecting males. They cripple the Intrinsic pathway.
Labs: Normal PT, severely prolonged aPTT. - Vitamin K Deficiency: Seen in severe malnutrition, fat malabsorption (cystic fibrosis), or prolonged antibiotic use (kills gut flora that make Vit K). Affects Factors II, VII, IX, X.
Labs: Prolonged PT (very sensitive to Factor VII loss) and prolonged aPTT. - Liver Disease (Cirrhosis): The liver synthesizes almost all coagulation factors. Liver failure causes severe, multi-factorial bleeding tendencies.
Labs: Prolonged PT/INR, prolonged aPTT, low platelets (due to portal hypertension/splenomegaly).
Pathology Spotlight: Disseminated Intravascular Coagulation (DIC)
DIC is a catastrophic, paradoxical syndrome often triggered by severe sepsis, massive trauma, or obstetric emergencies. The massive systemic inflammation aggressively triggers the coagulation cascade everywhere at once, forming thousands of micro-clots throughout the body (causing organ failure and tissue necrosis). Because the body uses up ALL its platelets and coagulation factors making these micro-clots, the patient then begins to bleed uncontrollably from every orifice and IV site. It is a "consumption coagulopathy."
DIC Labs: Massively decreased Platelets, massively prolonged PT and aPTT, deeply low Fibrinogen, and a sky-high D-Dimer (due to the body frantically trying to dissolve all the micro-clots).
C. Thrombotic Disorders (Thrombophilia)
Conditions where the blood clots far too easily, leading to Deep Vein Thrombosis (DVT) or Pulmonary Embolisms (PE).
- Inherited Thrombophilias:
- Factor V Leiden: The most common genetic cause. A mutation makes Factor V highly resistant to being deactivated by Activated Protein C (APC). The cascade cannot be turned off.
- Prothrombin G20210A Mutation: Causes overproduction of prothrombin.
- Deficiencies of Natural Anticoagulants: Rare but severe genetic lack of Antithrombin, Protein C, or Protein S.
- Acquired Thrombophilias:
- Antiphospholipid Syndrome (APS): An autoimmune disorder where antibodies attack phospholipids, creating a highly pro-thrombotic state (often causing recurrent miscarriages). Lab paradox: APS causes clotting in the patient, but artificially prolongs the aPTT in a test tube.
- Heparin-Induced Thrombocytopenia (HIT): An immune reaction to Heparin drugs that causes widespread, deadly platelet activation and thrombosis.
- Other Causes: Cancer (malignancy secretes pro-coagulant mucins), Pregnancy (high estrogen increases clotting factors), and prolonged immobilization (surgery, long flights).
VIII. References and Further Reading
- Kumar, V., Abbas, A. K., & Aster, J. C. (2020). Robbins & Cotran Pathologic Basis of Disease (10th ed.). Elsevier. (Chapter on Hemodynamic Disorders, Thromboembolism, and Shock).
- Hall, J. E., & Hall, M. E. (2020). Guyton and Hall Textbook of Medical Physiology (14th ed.). Elsevier. (Chapter on Hemostasis and Blood Coagulation).
- Hoffman, R., Benz Jr, E. J., Silberstein, L. E., et al. (2017). Hematology: Basic Principles and Practice (7th ed.). Elsevier.
- Loscalzo, J., Fauci, A., Kasper, D., et al. (2022). Harrison's Principles of Internal Medicine (21st ed.). McGraw Hill. (Disorders of Hemostasis section).
Platelets and Hemostasis
Test your knowledge with these 25 questions.
Platelets and Hemostasis Quiz
Question 1/25
Quiz Complete!
Here are your results, .
Your Score
23/25
92%
Platelets and Hemostasis Read More »
White Blood Cells (Leukocytes) Physiology
White Blood Cells (Leukocytes)
By the conclusion of this exhaustive master guide, you will be deeply conversant with:
- The detailed morphology, abundance, and highly specific physiological functions of the five major classes of Leukocytes.
- The exact, step-by-step hematological pathways of Leukopoiesis, including progenitor lineage and regulatory cytokines.
- Comprehensive profiles of Quantitative, Qualitative, and Malignant WBC Disorders, complete with clinical presentations and diagnostic markers.
- The advanced clinical interpretation of the Differential WBC Count and absolute cell metrics in diagnostics.
I. Introduction to White Blood Cells (Leukocytes)
White blood cells (WBCs), also known as leukocytes, form the mobile, intelligent defensive army of the human body. Circulating continuously through the cardiovascular and lymphatic systems, they are fundamentally distinct from red blood cells (erythrocytes). Unlike RBCs, mature leukocytes are complete, true cells—they possess a distinct nucleus, active mitochondria, a Golgi apparatus, and the ability to manufacture proteins.
While confined to the bloodstream for rapid transport, their true battleground lies in the tissue spaces. Leukocytes possess a unique capability called diapedesis (or extravasation)—the ability to physically squeeze through the intact endothelial walls of capillaries to hunt pathogens directly in the interstitial fluid.
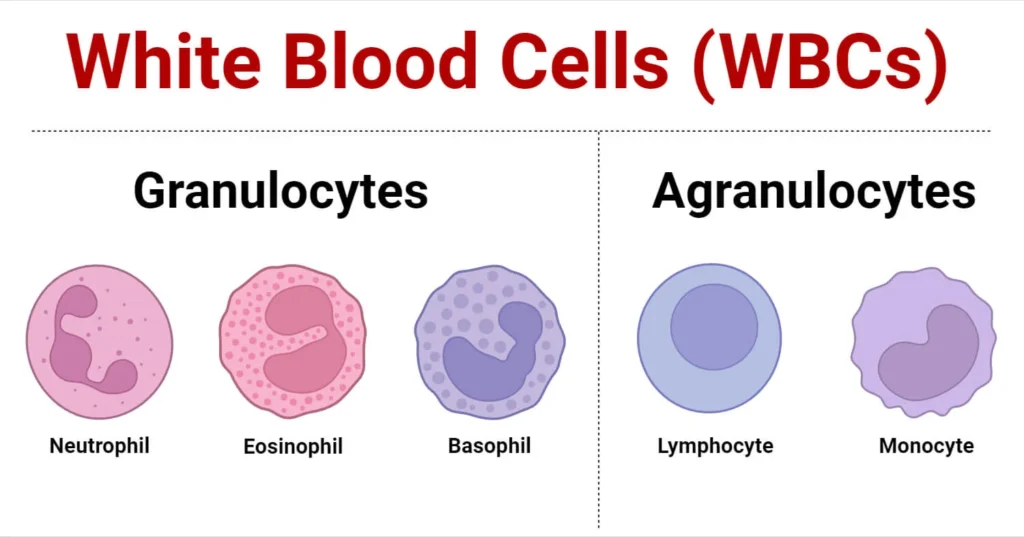
A normal adult has a WBC count ranging from 4,500 to 11,000 cells per microliter (μL) of blood. Based on the presence or absence of visible, chemical-filled vesicles (granules) when stained with standard Romanowsky stains (like Wright's or Giemsa), leukocytes are distinctly classified into two major categories: Granulocytes and Agranulocytes.
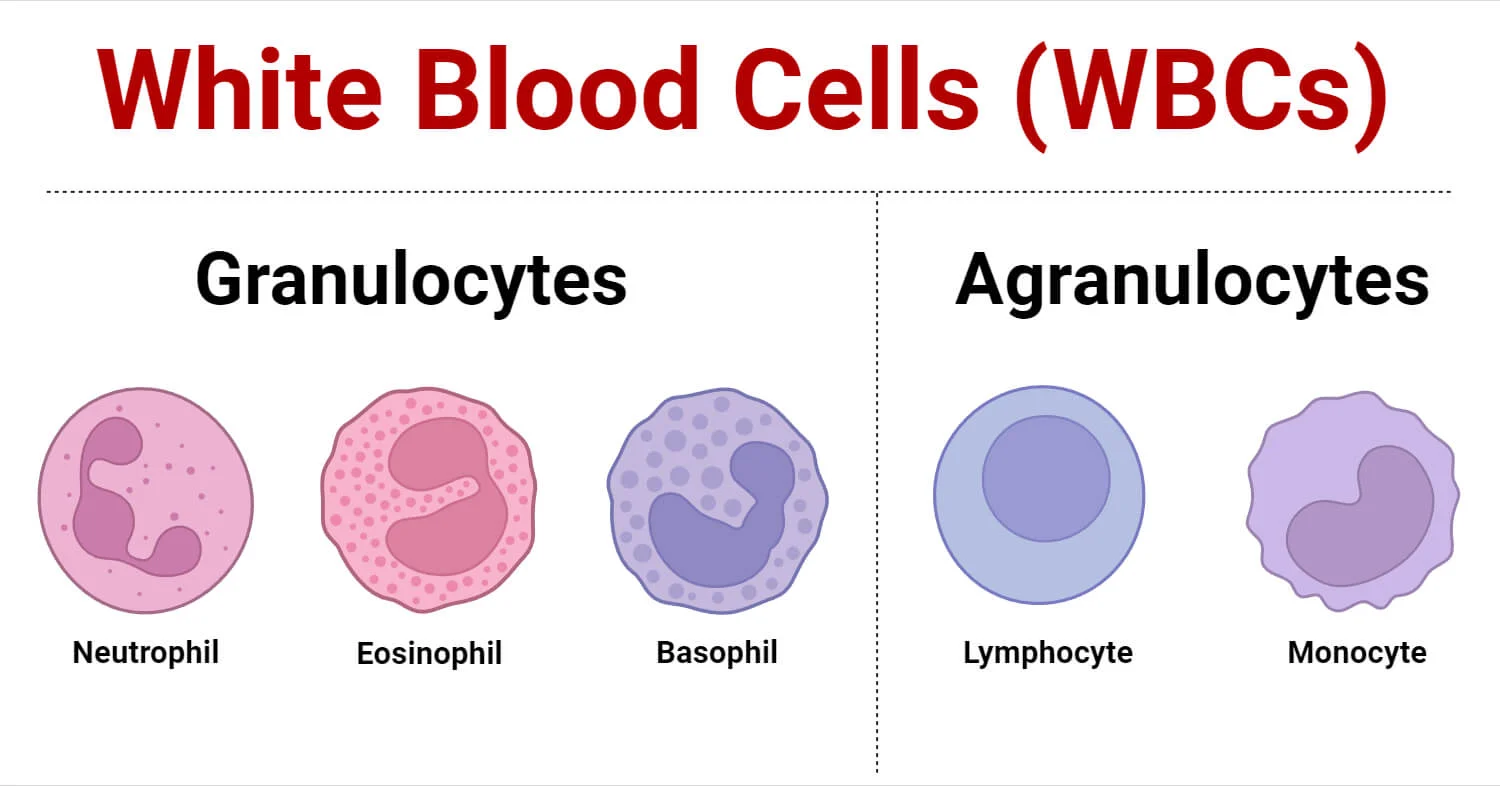
II. Category 1: The Granulocytes
Granulocytes are characterized by lobed, oddly shaped nuclei and cytoplasm packed with highly visible, reactive granules containing destructive enzymes, inflammatory mediators, and antimicrobial peptides. Because of their multi-lobed nuclei, they are often referred to clinically as Polymorphonuclear Leukocytes (PMNs), though this term is most strictly applied to neutrophils.
The First Responders (50-70% of total WBCs)
Morphology:
- Nucleus: Highly polymorphic, consisting of 2 to 5 distinct lobes connected by incredibly thin strands of chromatin. As a neutrophil ages, it gains more lobes. (Clinical Note: In females, a drumstick-shaped appendage called a Barr body—the inactivated X chromosome—is sometimes visible on one lobe).
- Cytoplasm: Packed with fine, pale lilac or pinkish-tan granules that stain neutrally (hence the name "neutrophil").
- Size: 10-14 μm in diameter.
Primary Functions & Deep Mechanisms:
- Rapid Phagocytosis: They are the acute phase responders to bacterial and fungal infections. They follow chemical trails (chemotaxis) to the site of infection.
- The Respiratory Burst: Once a bacterium is engulfed into a phagosome, the neutrophil unleashes a lethal "respiratory burst" (oxidative burst), creating massive amounts of superoxide anions, hydrogen peroxide, and bleach (hypochlorous acid via the enzyme Myeloperoxidase) to instantly vaporize the pathogen.
- Pus Formation: Neutrophils are essentially "kamikaze" cells. They fight fiercely, live for only 1 to 2 days in the tissues, and die. The accumulation of dead neutrophils, digested tissue, and dead bacteria forms the clinical exudate known as pus.
The Parasite Hunters (1-4% of total WBCs)
Morphology:
- Nucleus: Characteristically bi-lobed, frequently resembling an old-fashioned telephone receiver, a pair of eyeglasses, or headphones.
- Cytoplasm: Stuffed with large, coarse, uniform granules that stain a brilliant, fiery red-orange with eosin (an acidic dye). Under electron microscopy, these granules contain a distinct crystalline core.
- Size: 12-17 μm.
Primary Functions & Deep Mechanisms:
- Anti-Parasitic Warfare: Multicellular parasites (like tapeworms, hookworms, and flukes) are physically too massive for a single WBC to phagocytize. Eosinophils surround the worm and exocytose their toxic granules (specifically Major Basic Protein - MBP), which acts like acid, dissolving the parasite's tough outer cuticle.
- Allergy Modulation: They accumulate heavily in tissues during asthma attacks and severe hay fever. Interestingly, they play a dual role: they both promote tissue remodeling in asthma and release enzymes like histaminase to safely break down excess histamine, preventing allergic reactions from becoming uncontrollably fatal.
The Inflammatory Initiators (0.5-1% of total WBCs - The Rarest)
Morphology:
- Nucleus: Bi-lobed or S-shaped, but it is notoriously difficult to see because it is almost entirely obscured by the massive cytoplasmic granules.
- Cytoplasm: Contains immense, coarse, dark blue-purple granules (which have an affinity for basic dyes, hence "basophil").
- Size: 10-14 μm.
Primary Functions & Deep Mechanisms:
- Anaphylaxis and Allergy: The granules are essentially bombs filled with Histamine (a powerful vasodilator that causes vessels to leak fluid, producing redness and swelling) and Heparin (a potent anticoagulant preventing blood clotting in the infected area).
- IgE Cross-Linking: Basophils carry specific receptors for IgE antibodies. When an allergen (like peanut protein or bee venom) binds to these IgE antibodies on the basophil surface, the cell violently degranulates, triggering anaphylactic shock.
- Note: While functionally almost identical to tissue-dwelling Mast Cells, Basophils are distinctly different entities originating from different precursor pathways in the bone marrow.
III. Category 2: The Agranulocytes (Mononuclear Leukocytes)
Agranulocytes lack the dense, visually prominent specific granules found in granulocytes (though they do contain fine, non-specific lysosomes). Their nuclei are typically massive, rounded, un-lobed, or kidney-shaped.
1. Lymphocytes (20-40% of total WBCs)
Lymphocytes are the supreme generals of the Adaptive (Specific) Immune System. They do not just blindly attack anything foreign; they memorize specific pathogens and launch highly targeted strikes.
- Morphology: The nucleus is large, densely stained (dark purple), and perfectly round, taking up almost the entire volume of the cell. The cytoplasm is reduced to a tiny, pale-blue crescent rim around the nucleus. They range from small (7-9 μm) to large reactive forms.
- T Lymphocytes (T Cells): Responsible for Cell-Mediated Immunity.
- Cytotoxic T Cells (CD8+): The assassins. They seek out and inject lethal toxins (perforins and granzymes) directly into host cells that have been infected by viruses, or cells that have turned cancerous.
- Helper T Cells (CD4+): The commanders. They secrete cytokine signals that direct the entire immune response, telling macrophages to eat faster and B cells to produce antibodies. (These are the specific cells destroyed by the HIV virus).
- B Lymphocytes (B Cells): Responsible for Humoral (Antibody-Mediated) Immunity. Upon encountering a specific pathogen, B cells transform into massive factory cells called Plasma Cells. Plasma cells pump out millions of Y-shaped target-seeking missiles known as Antibodies (IgG, IgA, IgM, IgE) into the blood. Some B cells remain behind for decades as "Memory B Cells," granting lifelong immunity to diseases like measles.
- Natural Killer (NK) Cells: A unique subset that acts as a bridge to innate immunity. They patrol the body constantly and instantly destroy tumor cells or virus-infected cells without needing prior sensitization or memory.
2. Monocytes (2-8% of total WBCs)
Monocytes are the largest cells in the peripheral blood. They are the highly capable precursor cells of the tissue macrophage system.
- Morphology: Massive cells (14-20 μm) with a distinctive, indented, kidney-bean or horseshoe-shaped nucleus. The cytoplasm is abundant and has a dusty, pale gray-blue "ground-glass" appearance, often containing visible vacuoles (empty bubbles used for eating debris).
- The "Big Eaters" Transformation: Monocytes only circulate in the blood for 1 to 3 days. They then permanently exit the bloodstream, enter the tissues, and undergo a massive physical transformation into Macrophages. Based on where they settle, they get special names:
- Kupffer cells: In the liver.
- Microglia: In the central nervous system.
- Alveolar macrophages: In the lungs.
- Osteoclasts: In the bone.
- Antigen Presentation: After a macrophage devours a bacterium, it doesn't just destroy it. It acts as an Antigen-Presenting Cell (APC). It takes a piece of the dead bacterium, places it on a receptor (MHC Class II) on its own surface, and physically travels to a lymph node to "show" it to T-Helper cells, effectively sounding the alarm to start a specific immune war.
| WBC Type | Cytoplasm / Granules | Nucleus Morphology | Normal Abundance | Primary Clinical Function |
|---|---|---|---|---|
| Neutrophil | Fine, pale lilac, neutral. | 2-5 lobes, polymorphous. | 50-70% | Phagocytosis of bacteria/fungi; forming pus (acute first responders). |
| Lymphocyte | None/scant pale blue rim. | Large, round, dense, fills cell. | 20-40% | Specific adaptive immunity (T-cell assassins, B-cell antibodies), viral defense. |
| Monocyte | Dust-like, gray-blue, vacuolated. | Kidney-bean or horse-shoe shaped. | 2-8% | Transforms into Macrophages; heavy phagocytosis, antigen presentation. |
| Eosinophil | Large, brilliant red-orange. | Bi-lobed (headphone shape). | 1-4% | Destroys multicellular parasites (helminths); modulates severe allergies. |
| Basophil | Massive, dark blue-purple. | Bi-lobed, often obscured by granules. | 0.5-1% | Initiates severe allergic reactions/anaphylaxis (releases histamine/heparin). |
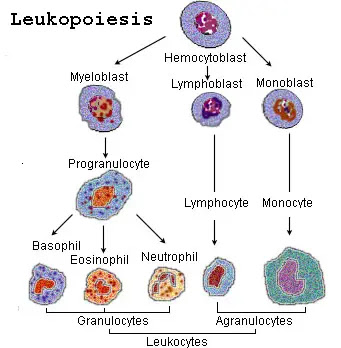
IV. The Process of Leukopoiesis (WBC Production)
Leukopoiesis is the highly orchestrated, continuous process of white blood cell production. It occurs primarily in the highly cellular red bone marrow (found heavily in the pelvis, sternum, ribs, and vertebrae in adults). Unlike erythropoiesis (red blood cell production), which is driven mostly by a single hormone (erythropoietin from the kidneys), leukopoiesis is governed by an incredibly complex chemical network of growth factors known as Colony-Stimulating Factors (CSFs) and Interleukins (ILs).
1. The Master Cell: Hematopoietic Stem Cells (HSCs)
Every single blood cell in your body begins as an identical, pluripotent Hematopoietic Stem Cell (HSC) in the bone marrow. These HSCs possess the ultimate ability to self-renew and to differentiate into two mutually exclusive progenitor pathways:
- The Common Myeloid Progenitor (CMP): The "factory" that produces the raw, non-specific blood cells: Granulocytes, Monocytes, Red Blood Cells, and Platelets (Megakaryocytes).
- The Common Lymphoid Progenitor (CLP): The specialized "factory" that strictly produces specific immune cells: T cells, B cells, and Natural Killer (NK) cells.
The Stages of Myelopoiesis (Creating Granulocytes)
The journey from a stem cell to a fully armed, multi-lobed Neutrophil is a 14-day process involving drastic morphological changes. Pathologists study these exact stages in bone marrow biopsies to diagnose leukemias.
- Myeloblast: The very first morphologically recognizable precursor. It is a massive cell with a huge nucleus, prominent nucleoli, and purely blue (basophilic) cytoplasm with absolutely no granules. (Finding Myeloblasts in peripheral circulating blood is severely abnormal and is the defining diagnostic hallmark of Acute Myeloid Leukemia - AML).
- Promyelocyte: The cell grows even larger. Crucially, the cell begins manufacturing primary (azurophilic) granules. These are dark purple, lethal lysosomes.
- Myelocyte: A critical turning point. The cell begins synthesizing specific (secondary) granules. This is the moment the cell officially commits to becoming either a neutrophil, eosinophil, or basophil. The nucleus begins to flatten. This is the last stage capable of cellular division (mitosis).
- Metamyelocyte: The nucleus becomes deeply indented, taking on a distinct kidney-bean shape. The cell stops dividing and focuses purely on maturation.
- Band Cell (Stab Cell): The nucleus becomes elongated, thin, and curved like a "C" or a horseshoe, but it has not yet segmented into distinct lobes. (Clinical goldmine: A high number of Band Cells released into the blood is called a "Left Shift," indicating the bone marrow is frantically pumping out immature soldiers to fight a massive bacterial infection).
- Mature Segmented Granulocyte: The nucleus completely pinches into distinct, thin-threaded lobes. The fully mature cell is released into the bloodstream.
2. Lymphopoiesis (Creating Lymphocytes)
The Common Lymphoid Progenitor (CLP) differentiates into a Lymphoblast, then a Prolymphocyte, and finally a mature Lymphocyte. However, their maturation locations are highly unique:
- B Lymphocytes: Born in the Bone marrow, and they stay in the Bone marrow to fully mature and learn how to make antibodies before migrating to lymph nodes.
- T Lymphocytes: Born in the bone marrow, but they immediately migrate to the Thymus gland (in the chest) to undergo a rigorous, brutal maturation and selection process. If a T-cell accidentally reacts to the body's own tissue, the Thymus forces it to commit apoptosis (cell suicide) to prevent autoimmune diseases.
3. Chemical Regulation of Leukopoiesis
The bone marrow relies on cytokine signals to know exactly what type of WBC the body needs at any given moment.
- GM-CSF (Granulocyte-Macrophage CSF): A broad-spectrum stimulator forcing myeloid progenitors to aggressively produce both granulocytes and monocytes.
- G-CSF (Granulocyte CSF): A highly specific hormone that commands the marrow to produce almost exclusively Neutrophils.
Clinical Application: Pharmacologists synthesize this hormone as a drug called Filgrastim (Neupogen). It is injected into cancer patients undergoing heavy chemotherapy to forcefully rescue them from deadly neutropenia (total loss of neutrophils). - M-CSF (Macrophage CSF): Promotes the differentiation of monocytes into tissue-destroying macrophages.
- Interleukin-3 (IL-3): A multilineage master switch; stimulates early stem cell growth across the board.
- Interleukin-5 (IL-5): The definitive, crucial cytokine required for the growth, differentiation, and explosive release of Eosinophils (levels spike heavily during parasitic worm infections).
- Interleukin-7 (IL-7): The master regulator essential for the survival and development of B and T lymphocytes.
V. Common Disorders Associated with White Blood Cells
Disorders involving white blood cells are highly diverse, ranging from simple numerical responses to severe infections, to devastating genetic functional defects, all the way to terminal malignant cancers.
1. Quantitative Disorders (Abnormalities in Number)
A. Leukocytosis (Too Many WBCs)
Definition: A total white blood cell count exceeding the upper normal limit (>11,000 WBCs/μL).
- Physiologic Causes: Pregnancy, extreme physical exertion, emotional stress, and high cortisol levels cause WBCs stuck to the walls of blood vessels (the marginating pool) to suddenly detach and float freely, artificially raising the blood count without actual new production.
- Pathologic Causes:
- Neutrophilia: Driven heavily by acute bacterial infections (pneumonia, appendicitis) or sterile tissue necrosis (a severe myocardial infarction / heart attack).
- Leukemoid Reaction: A massive, extreme, but benign elevation of WBCs (often >50,000/μL) in response to profound infection (like sepsis) or severe hemorrhage. It mimics leukemia on paper, but the cells are benign, functional responders.
- Lymphocytosis: Classic presentation of acute viral infections (e.g., Infectious Mononucleosis / Epstein-Barr Virus).
- Eosinophilia: Classic presentation of severe allergic asthma, systemic drug reactions, or parasitic helminthic infections (e.g., Ascaris, Schistosoma).
B. Leukopenia (Too Few WBCs)
Definition: A total white blood cell count dropping dangerously below the normal range (<4,000 WBCs/μL).
- Neutropenia (Agranulocytosis): The most clinically terrifying form of leukopenia. Without neutrophils, a patient loses their primary defense against basic bacteria. Minor infections rapidly escalate to lethal septic shock.
Causes include: Heavy radiation therapy, cytotoxic chemotherapy, severe viral destruction of the marrow (HIV/AIDS), or idiosyncratic, deadly reactions to certain medications (e.g., the antipsychotic Clozapine or the anti-thyroid drug Propylthiouracil). - Lymphopenia: Severe depletion of lymphocytes. Seen classically in end-stage HIV/AIDS (which specifically targets and eradicates CD4+ Helper T cells), causing the patient to succumb to bizarre, opportunistic infections.
2. Qualitative Disorders (Abnormal Function or Morphology)
In these genetic disorders, the patient may have a perfectly normal *number* of WBCs, but the cells are structurally defective or biochemically "blind" and useless.
An inherited, benign condition where neutrophils fail to segment properly. The nucleus is permanently hyposegmented (bilobed or entirely unlobed), resembling a classic "pince-nez" (old-fashioned pinching eyeglasses). While structurally bizarre, the cells usually function normally.
A severe, rare autosomal recessive genetic disorder characterized by a defect in microtubule polymerization. The lysosomes in the WBCs cannot fuse with phagosomes.
Hallmarks: Massive, abnormal, giant granules visible in phagocytes; severe albinism (defect in melanin transport); severe peripheral neuropathy; and highly lethal, recurrent pyogenic infections.
A fatal X-linked or autosomal recessive disorder where the neutrophils completely lack the NADPH oxidase enzyme. They can eat bacteria, but they cannot produce the "respiratory burst" (superoxide/bleach) to kill them. Bacteria survive happily inside the neutrophil.
Diagnosis: Diagnosed using the specialized Nitroblue Tetrazolium (NBT) test or Dihydrorhodamine (DHR) flow cytometry. Patients suffer massive, recurrent abscesses from catalase-positive organisms (like Staphylococcus aureus and Aspergillus).
3. Malignant Disorders (Cancers of the White Blood Cells)
When the highly complex genetic code controlling leukopoiesis mutates, WBC precursors begin dividing uncontrollably, refusing to mature, and refusing to die. These malignant clones overrun the bone marrow and systematically destroy the host.
A. The Leukemias ("White Blood")
Cancers originating directly inside the bone marrow, characterized by the explosive proliferation of abnormal, entirely useless, immature WBCs (known as blasts) that pack the marrow space and spill out into the peripheral circulating blood. Because the marrow is choked by blasts, it stops making normal RBCs and platelets, leading to the clinical triad of: Severe Anemia (fatigue), Thrombocytopenia (severe bleeding/bruising), and Neutropenia (massive infections despite a high total WBC count).
- Acute Leukemias: Extremely rapid, aggressive onset. The cells are highly primitive "blasts" that do not function. If untreated, death occurs in weeks to months.
- Acute Lymphoblastic Leukemia (ALL): The most common childhood cancer. Responds well to targeted chemotherapy.
- Acute Myeloid Leukemia (AML): Primarily affects older adults. Pathologists diagnose it by finding characteristic needle-like crystal inclusions called Auer rods inside the myeloblast cytoplasm.
- Chronic Leukemias: Slower, insidious onset spanning years. The mutated cells are more mature, but still functionally abnormal.
- Chronic Myeloid Leukemia (CML): Famously driven by a highly specific genetic chromosomal translocation: t(9;22), creating the Philadelphia Chromosome. This creates a hyperactive tyrosine kinase enzyme. Modern medicine treats this brilliantly with targeted enzyme inhibitors like Imatinib (Gleevec).
- Chronic Lymphocytic Leukemia (CLL): The most common leukemia in Western adults. Often asymptomatic for decades. Characterized on a blood smear by fragile, broken lymphocytes known as "smudge cells."
B. The Lymphomas
Cancers that originate as solid tumors within the secondary lymphatic system (the lymph nodes, spleen, or thymus) rather than floating freely in the blood. They classically present as painless, progressively enlarging, rubbery lymph nodes (lymphadenopathy) accompanied by "B symptoms" (severe drenching night sweats, unexplained spiking fevers, and massive unexplained weight loss).
- Hodgkin Lymphoma (HL): Highly curable. It spreads in an orderly, predictable, contiguous chain from one lymph node group to the next. The absolute diagnostic hallmark is the presence of massive, malignant, multi-nucleated cells that look exactly like an owl's face, known as Reed-Sternberg cells.
- Non-Hodgkin Lymphoma (NHL): A massive, diverse group of highly aggressive B-cell, T-cell, or NK-cell tumors. They spread erratically to non-contiguous lymph nodes and extranodal organs (like the GI tract or brain). Examples include Burkitt Lymphoma (associated with the Epstein-Barr Virus and jaw tumors in Africa) and Diffuse Large B-Cell Lymphoma (DLBCL).
C. Multiple Myeloma
A devastating, specific malignancy of terminally differentiated B-cells (Plasma Cells). Instead of making useful antibodies, the cancerous plasma cells proliferate inside the bone marrow and pump out millions of identical, useless, defective antibodies known as Monoclonal M-proteins. They also produce free light chains (Bence Jones proteins) that travel through the blood and physically clog and destroy the kidneys.
Clinical Hallmarks (The CRAB Criteria):
- C: Calcium elevation (hypercalcemia) due to massive bone destruction.
- R: Renal (Kidney) failure due to toxic Bence Jones proteins.
- A: Anemia due to the marrow being choked by plasma cells.
- B: Bone lesions. The cancer cells secrete chemicals that activate osteoclasts, which literally eat "punched-out" lytic holes into the patient's skull, ribs, and spine, leading to agonizing bone pain and sudden, spontaneous fractures.
VI. Clinical Significance of a Differential White Blood Cell Count
A Complete Blood Count (CBC) with a "Differential" is arguably the most profoundly useful routine diagnostic blood test in modern medicine. While the total WBC count tells you if there is an immune response, the Differential Count breaks down exactly *which* of the five types of WBCs are participating in the battle. This gives the clinician a highly accurate "fingerprint" of the underlying disease process.
1. How a Differential is Performed
- Automated Flow Cytometry: Modern, high-tech hematology analyzers shoot a laser beam through a microscopic stream of blood. As thousands of cells pass the laser one by one, the machine analyzes the light scatter to instantly determine the exact size, nuclear complexity, and granular density of each individual cell, producing a highly accurate graph.
- Manual Peripheral Blood Smear: If the automated machine detects bizarre, immature blasts or highly atypical cells, a specialized hematology technologist takes a drop of the patient's blood, smears it onto a glass slide, stains it with Giemsa, and physically examines 100 consecutive white blood cells under a high-power microscope to visually confirm the pathology.
2. Interpreting the Differential: Absolute Counts vs. Percentages
A critical clinical rule: Absolute counts are always more important than percentages. If a patient has a massive total WBC count of 50,000, and their lymphocytes represent 10%, they still have 5,000 lymphocytes (which is a high absolute number), even though the percentage looks falsely "low."
Diagnostic Interpretation Patterns
- High Total WBC + Severe Neutrophilia (e.g., 85% Neutrophils) + "Left Shift" (Band Cells):
The classic fingerprint of an Acute Bacterial Infection (like pneumococcal pneumonia, acute appendicitis, or bacterial meningitis). The marrow is fighting a massive bacterial war. - Normal/Slightly High Total WBC + Severe Lymphocytosis (e.g., 60% Lymphocytes) + Atypical Reactive Lymphocytes:
The classic fingerprint of an Acute Viral Infection (e.g., Infectious Mononucleosis / Epstein-Barr, Cytomegalovirus, or viral hepatitis). Viruses hide inside cells, so the body relies entirely on Lymphocytes (T-cell assassins) to kill them, completely ignoring neutrophils. - High Eosinophils (Eosinophilia - e.g., 15%): + Skin Rash or Wheezing:
Highly indicative of an intense systemic Allergic Reaction (severe asthma, drug hypersensitivity, eczema) OR an invasive Parasitic Helminth Infection (like Hookworm or Strongyloides). - Massive Total WBC (e.g., 100,000/μL) + High Monocytes + High Neutrophils + Basophilia:
Often the suspicious fingerprint of a Myeloproliferative Disorder, particularly Chronic Myeloid Leukemia (CML). - Severe Neutropenia (Absolute Neutrophil Count / ANC < 500/μL) + Fever:
This is known as Febrile Neutropenia. It is a massive, life-threatening medical emergency often seen in chemotherapy patients. Because they have zero neutrophils, a simple fever means they have a bacterial infection that will progress to fatal septic shock in hours if not treated immediately with aggressive, broad-spectrum IV antibiotics.
VII. List of References for Further Reading
The exhaustive pathophysiological details, classifications, and diagnostic criteria provided in this master guide are drawn from and corroborated by the following gold-standard medical texts and hematological guidelines:
- Kumar, V., Abbas, A. K., & Aster, J. C. (2020). Robbins and Cotran Pathologic Basis of Disease (10th ed.). Elsevier. (Definitive text for leukocyte pathology, leukemias, and lymphomas).
- Hoffbrand, A. V., & Steensma, D. P. (2019). Hoffbrand's Essential Haematology (8th ed.). Wiley-Blackwell. (Gold standard for leukopoiesis, bone marrow morphology, and blood smear interpretations).
- Hall, J. E., & Hall, M. E. (2020). Guyton and Hall Textbook of Medical Physiology (14th ed.). Elsevier. (Definitive resource on the physiological mechanisms of phagocytosis, innate immunity, and the respiratory burst).
- Loscalzo, J., Fauci, A. S., Kasper, D. L., Hauser, S. L., Longo, D. L., & Jameson, J. L. (2022). Harrison's Principles of Internal Medicine (21st ed.). McGraw Hill. (Standard reference for the clinical interpretation of the differential WBC count, neutropenic emergencies, and multiple myeloma CRAB criteria).
- Abbas, A. K., Lichtman, A. H., & Pillai, S. (2021). Cellular and Molecular Immunology (10th ed.). Elsevier. (Exhaustive detail on T-cell, B-cell, and NK-cell molecular functions and cytokine regulation).
White Blood Cells Quiz
Test your knowledge with these 30 questions.
White Blood Cells Quiz
Question 1/30
Quiz Complete!
Here are your results, .
Your Score
27/30
90%
White Blood Cells (Leukocytes) Physiology Read More »
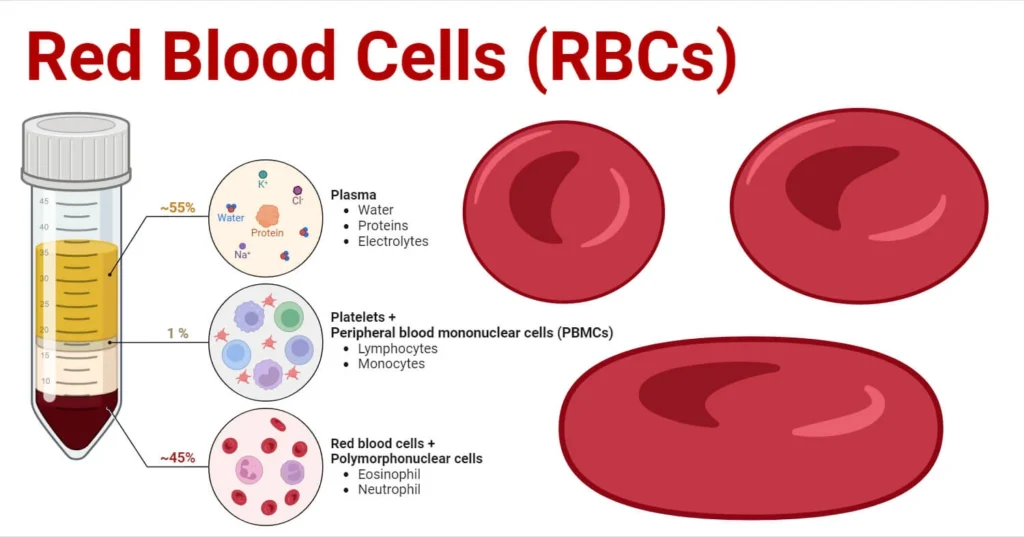
Red Blood Cells (Erythrocytes) Physiology
Erythrocytes, Hemoglobin, and Cellular Metabolism
By the conclusion of this exhaustive master guide, you will be deeply conversant with:
- The unique anatomical and structural adaptations of the Red Blood Cell (RBC).
- The intricate molecular architecture and functionality of Hemoglobin, including gas transport dynamics.
- The four specialized metabolic pathways of the erythrocyte that ensure its survival and function without organelles.
- The complete lifecycle of the erythrocyte: from Erythropoiesis in the bone marrow to Senescence and Destruction in the reticuloendothelial system.
Section I: Anatomy & Structural Physiology of the Erythrocyte
Red blood cells (RBCs), clinically referred to as erythrocytes, are arguably the most crucial cellular component of blood in terms of overall physiological function and homeostasis. Their primary mandate is the transport of life-sustaining oxygen from the pulmonary capillaries to the peripheral tissues, and the simultaneous transport of toxic carbon dioxide from the tissues back to the lungs for expiration. To execute this relentless, heavy-duty mechanical and chemical task, erythrocytes possess a highly specialized, stripped-down cellular structure.
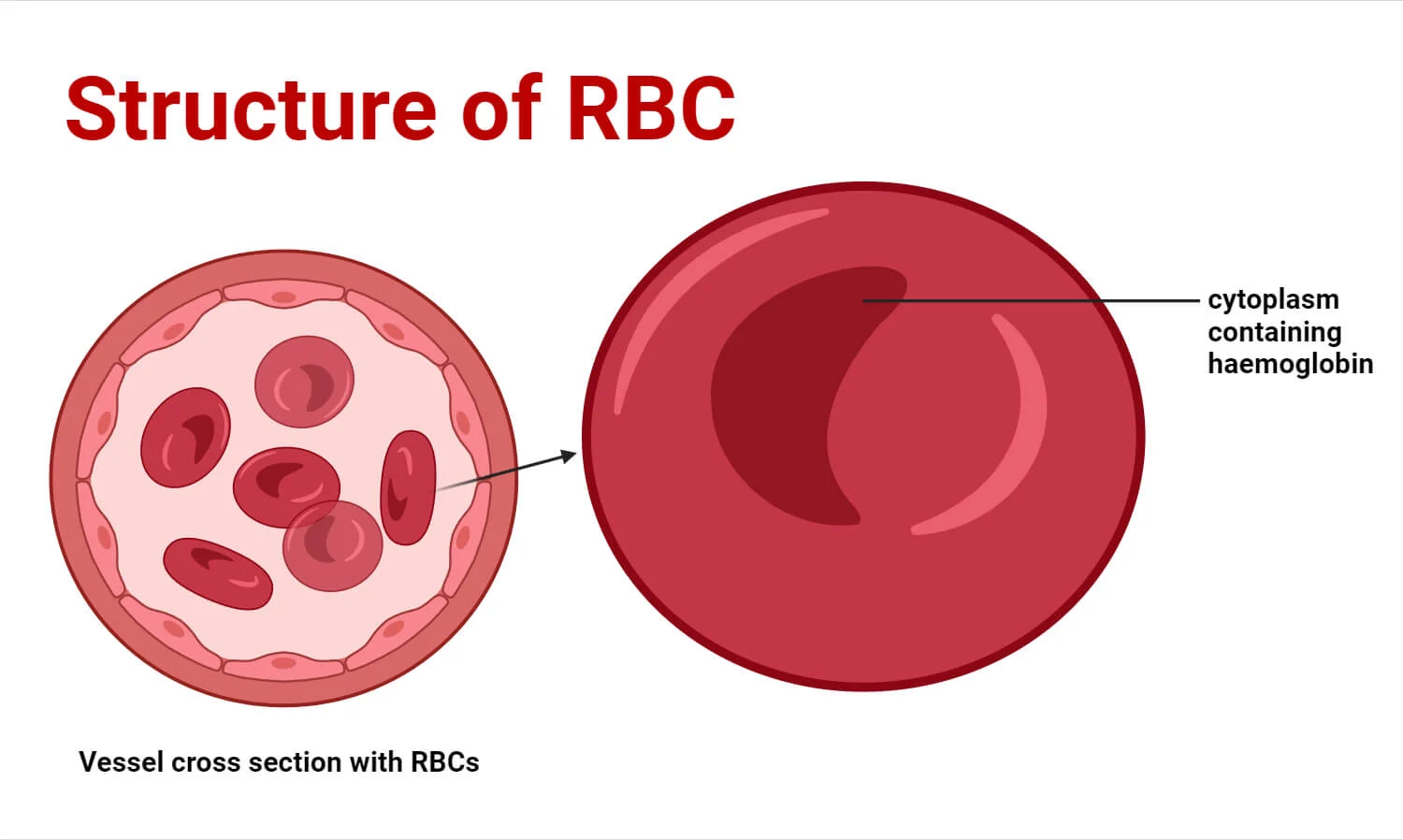
1. The Biconcave Disc Shape
Mature RBCs are incredibly flexible, anucleated entities. Their most visually defining characteristic is the biconcave disc shape—a flattened, doughnut-like structure with depressed, thinner centers on both sides. A normal erythrocyte measures approximately 7.5 µm in diameter, 2.0 µm in thickness at the extreme edges, and a mere 1.0 µm in the depressed center.
Functional Significance of the Biconcave Shape:
- Maximized Surface Area to Volume Ratio: This geometry provides a surface area approximately 30% greater than that of a sphere of the same volume. This massive surface area is absolutely critical for the rapid, efficient diffusion of O2 and CO2 gases across the cell membrane.
- Extreme Flexibility and Deformability: The human microvasculature contains capillaries that are often only 3 to 4 µm in diameter. An RBC (7.5 µm) must literally fold itself in half, parachute-style, to squeeze through these narrow endothelial gaps. The biconcave shape allows excess membrane slack, enabling this extreme deformation without rupturing the cell.
- Rouleaux Formation: The flattened nature of the discs allows RBCs to stack neatly on top of one another like a roll of coins (Rouleaux). This prevents turbulent flow and allows cells to glide smoothly through narrow venules and capillaries without jamming or causing microvascular occlusions.
2. Anucleated State & Lack of Organelles
During the final stages of maturation in the bone marrow, the erythrocyte commits the ultimate cellular sacrifice: it forcibly extrudes its nucleus and aggressively dismantles its mitochondria, endoplasmic reticulum, and Golgi apparatus.
Functional Significance:
- Maximized Hemoglobin Payload: By jettisoning bulky organelles, the erythrocyte frees up maximum internal volume to be packed almost entirely with hemoglobin. Approximately 97% of the cell's dry weight (non-water content) is pure hemoglobin.
- Zero Oxygen Consumption: Because they completely lack mitochondria, RBCs cannot perform oxidative phosphorylation. Consequently, they do not consume even a fraction of the precious oxygen they are transporting to the tissues. They operate entirely on anaerobic glycolysis.
- Limited Cellular Lifespan: The evolutionary trade-off for this extreme specialization is a short life. Lacking a nucleus and ribosomes, the mature RBC has absolutely no protein synthesis machinery. It cannot repair damaged enzymes or replace worn-out membrane lipids, rigidly limiting its lifespan to approximately 100 to 120 days.
3. The Specialized Plasma Membrane
The erythrocyte plasma membrane is a standard phospholipid bilayer, but it is heavily fortified on its intracellular surface by a dense, dynamic network of cytoskeletal proteins (predominantly Spectrin, Ankyrin, Actin, and Band 3).
Functional Significance:
- Maintaining Structural Integrity: The spectrin-actin cytoskeletal lattice acts like a flexible molecular scaffolding. It acts like springs, allowing the membrane to endure the massive, continuous shear stress of arterial blood pressure, and immediately snapping the cell back into its biconcave shape once it exits a narrow capillary.
- Antigen Presentation: The outer leaflet of the membrane is heavily studded with highly specific glycoproteins and glycolipids. These molecules act as structural identity markers, the most clinically significant being the ABO blood group antigens and the Rh (Rhesus) factor antigens, which dictate blood transfusion compatibility.
Hereditary Spherocytosis
To truly understand the importance of the spectrin cytoskeleton, we examine the genetic disease Hereditary Spherocytosis. Patients with this condition inherit a genetic mutation that causes a deficiency in spectrin or ankyrin proteins. Without this structural scaffolding, the RBC cannot maintain its biconcave shape and instead assumes a rigid, spherical shape (a spherocyte).
Because these spherocytes lack flexibility, they become trapped in the narrow cords of the spleen. The splenic macrophages view them as abnormal and aggressively devour them, leading to severe, chronic hemolytic anemia, massive splenomegaly (enlarged spleen), and jaundice.
Section II: Primary Functions of the Erythrocyte
1. Oxygen Transport
This is the prime directive of the RBC. Hemoglobin (Hb) binds reversibly to oxygen.
- In the Pulmonary Capillaries (Lungs): The environment boasts a high partial pressure of oxygen (PO2). Oxygen diffuses rapidly across the alveolar membrane into the RBC, loading onto the hemoglobin to form Oxyhemoglobin (HbO2). This oxygen-rich state gives arterial blood its characteristic bright, vibrant red appearance.
- In the Peripheral Tissues: The metabolic activity of the tissues depletes oxygen, creating an environment with a low PO2. The chemical bond between oxygen and hemoglobin weakens, causing the O2 to rapidly unload and diffuse into the surrounding tissue cells.
2. Carbon Dioxide Transport
As a byproduct of cellular metabolism, tissues generate massive amounts of toxic carbon dioxide (CO2). The RBC acts as a garbage truck, transporting CO2 back to the lungs via three distinct physiological methods:
The Bicarbonate Buffer System
The vast majority of CO2 diffuses into the RBC where an incredibly fast enzyme, Carbonic Anhydrase, catalyzes its reaction with water to form carbonic acid (H2CO3). This unstable acid instantly dissociates into a Hydrogen ion (H+) and a Bicarbonate ion (HCO3-).
The newly formed Bicarbonate is pumped out of the RBC into the blood plasma in exchange for a Chloride ion coming in (the Chloride Shift or Hamburger phenomenon). The bicarbonate safely travels in the plasma to the lungs.
Carbaminohemoglobin
A significant portion of CO2 binds directly to the terminal amino groups of the hemoglobin's globin protein chains (it does not bind to the iron where oxygen sits). This forms Carbaminohemoglobin (HbCO2). This reaction is highly reversible and heavily dependent on the local PCO2 levels in the blood.
Dissolved in Plasma
Because carbon dioxide is substantially more highly soluble in water than oxygen, a small but notable fraction simply remains dissolved as free gas within the fluid matrix of the blood plasma.
3. Systemic pH Regulation (Buffering)
Hemoglobin is not just a transporter; it is an exceptional biological buffer. When Carbonic Anhydrase converts CO2 into bicarbonate and a free, highly acidic Hydrogen ion (H+), this threatens to catastrophically drop the blood pH. However, Deoxyhemoglobin (hemoglobin that has just dropped off its oxygen) has an incredibly high chemical affinity for H+ ions. It acts like a sponge, soaking up the free H+ ions, thereby preventing intracellular acidosis and maintaining strict systemic blood pH within the narrow, life-sustaining physiological window of 7.35 to 7.45.
Section III: Molecular Architecture and Function of Hemoglobin
Hemoglobin (Hb) is the specialized, complex globular protein completely responsible for the erythrocyte's gas-carrying capacity. It boasts a complex quaternary protein structure that is evolutionarily perfected for its role in gas exchange.
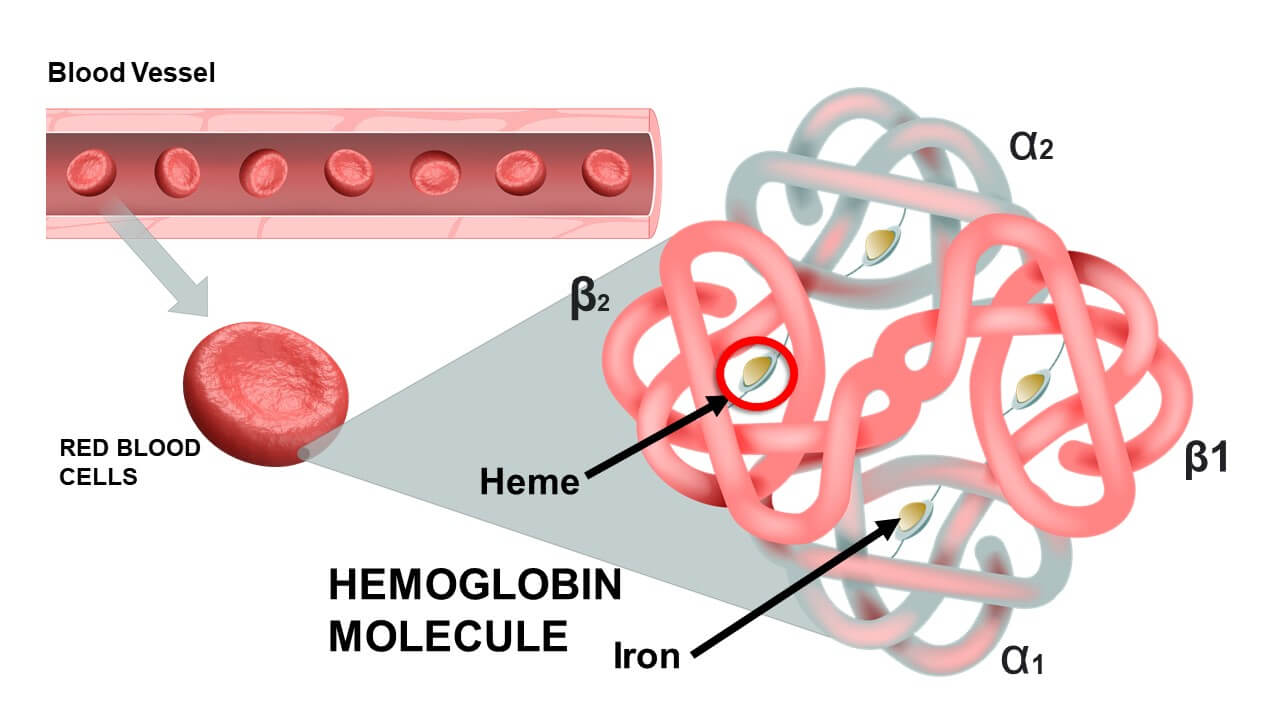
1. The Structure of Hemoglobin
- Four Polypeptide Chains (Globins): A single, complete hemoglobin molecule is constructed from four highly folded protein subunits. In healthy adults, the overwhelmingly dominant type (HbA) consists of two Alpha (α) chains and two Beta (β) chains. Each globin chain features a highly specific amino acid sequence folded into an intricate 3D structure.
- Four Heme Groups: Embedded deep within the folds of each of the four globin chains is a non-protein, iron-containing prosthetic group called a Heme group. Thus, 1 complete Hemoglobin molecule = 4 distinct Heme groups.
- The Porphyrin Ring: Specifically known as Protoporphyrin IX, this is a large, flat, complex organic ring structure.
- The Iron Ion (Fe2+): Suspended perfectly in the dead center of the porphyrin ring is a single iron ion. Critical Physiology: This iron MUST be maintained in the Ferrous (Fe2+) state. If it is oxidized to the Ferric (Fe3+) state, it forms Methemoglobin, which is utterly incapable of binding oxygen.
2. Advanced Functional Dynamics of Hemoglobin
A. Cooperative Binding and the Sigmoidal Curve
Hemoglobin does not bind oxygen passively; it utilizes a highly dynamic biochemical phenomenon known as Cooperative Binding (allosteric modification). In the deoxygenated state, hemoglobin exists in a tight, rigid conformation known as the T-State (Tense state), which has a low affinity for oxygen.
When the very first O2 molecule forces its way in and binds to one of the four heme groups, it breaks several salt bridges. This causes a dramatic conformational (shape) change in the entire hemoglobin molecule, snapping it into the R-State (Relaxed state). This shape change massively increases the chemical affinity of the remaining three empty heme groups for oxygen. As each oxygen binds, the next one binds even faster.
This cooperative action results in the classic S-shaped (sigmoidal) Oxygen-Hemoglobin Dissociation Curve. It ensures that Hb loads up completely in the lungs and unloads rapidly and massively the moment it detects low oxygen in the peripheral tissues.
B. The Bohr and Haldane Effects
- The Bohr Effect (Tissue Level): Increased CO2 and increased H+ (acidity) in actively working tissues physically forces hemoglobin to release its oxygen more readily.
- The Haldane Effect (Lung Level): Conversely, the high concentration of Oxygen in the lungs forces hemoglobin to aggressively dump its loaded CO2 and H+ ions so they can be exhaled. Oxygenation of blood in the lungs naturally displaces carbon dioxide from hemoglobin.
3. Variants and Types of Hemoglobin
The classification of hemoglobin types is based entirely on the specific composition of their polypeptide globin chains.
| Hemoglobin Type | Globin Chain Structure | Prevalence & Clinical Significance |
|---|---|---|
| Hemoglobin A (HbA) Adult |
2 Alpha (α) + 2 Beta (β) chains. (α2β2) |
The overwhelmingly dominant form in healthy adults, accounting for 95% to 98% of all circulating hemoglobin. |
| Hemoglobin A2 (HbA2) Minor Adult |
2 Alpha (α) + 2 Delta (δ) chains. (α2δ2) |
A normal, minor variant comprising roughly 1.5% to 3.5% of adult hemoglobin. |
| Hemoglobin F (HbF) Fetal |
2 Alpha (α) + 2 Gamma (γ) chains. (α2γ2) |
The primary hemoglobin of the developing fetus. Crucial Physiology: HbF does not bind 2,3-BPG well. Therefore, it has a vastly higher affinity for oxygen than adult HbA. This allows the fetal blood to literally "steal" oxygen across the placenta from the mother's red blood cells. |
Hemoglobinopathies: Sickle Cell and Thalassemia
Genetic defects in the DNA instructions for globin chains lead to devastating hemoglobinopathies.
- Sickle Cell Anemia: Caused by a single point mutation (Glutamic acid replaced by Valine) in the Beta-globin chain, creating abnormal HbS. Under low oxygen conditions, HbS molecules polymerize (clump together) into long, rigid crystalline rods. This physically distorts the RBC into a sharp, rigid "sickle" shape. These sickle cells rupture easily (hemolysis) and jam together to block small blood vessels, causing excruciating pain crises, organ ischemia, and tissue infarction.
- Thalassemias: Unlike Sickle Cell (where the protein is built wrong), Thalassemias occur when the bone marrow simply doesn't build enough of the protein. Alpha-Thalassemia is a decreased synthesis of Alpha chains; Beta-Thalassemia is a decreased synthesis of Beta chains. This results in tiny, pale RBCs (microcytic, hypochromic anemia) and severe oxygen starvation.
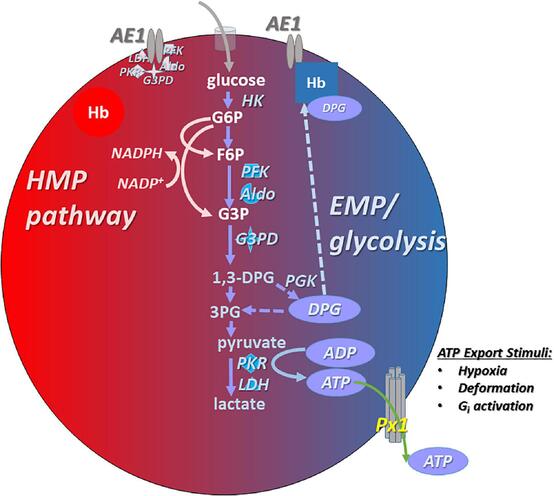
Section IV: Metabolic Pathways of the Erythrocyte
Because the mature red blood cell purposefully lacks a nucleus, mitochondria, and other complex organelles, it relies on a highly simplified, stripped-down, yet exquisitely specialized metabolic machinery. Its entire biochemistry is designed to do exactly two things: keep the cell alive and keep the hemoglobin functional.
1. Primary Energy Production: Anaerobic Glycolysis (Emden-Meyerhof Pathway)
The Dilemma: Lacking mitochondria, RBCs cannot perform oxidative phosphorylation or utilize the Krebs cycle. If they used the oxygen they transport for energy, they would steal it from the brain and heart.
The Solution: Glycolysis is the sole, exclusive pathway for ATP generation in the mature RBC. This pathway consumes glucose directly from the blood plasma, breaking it down into pyruvate, yielding a meager but essential net gain of 2 ATP molecules per glucose molecule.
The End Product: Without mitochondria to process the pyruvate, an enzyme called Lactate Dehydrogenase instantly converts the pyruvate into Lactate (lactic acid). This lactate diffuses out of the RBC into the plasma, travels to the liver, and is recycled back into glucose via gluconeogenesis (the Cori Cycle).
What does the RBC do with this ATP?
- Fueling Ion Pumps: ATP exclusively powers the membrane-bound Na+/K+-ATPase pumps. These pumps exhaustively eject sodium out of the cell to prevent water from rushing in via osmosis. If ATP fails, the cell swells and explodes (osmotic hemolysis).
- Cytoskeletal Maintenance: ATP is required to phosphorylate and maintain the elastic tension of the spectrin-actin lattice, keeping the cell biconcave.
2. The Hexose Monophosphate (HMP) Shunt / Pentose Phosphate Pathway
While this side pathway produces exactly zero ATP, it is the only thing keeping the RBC from oxidizing and rusting from the inside out.
- The Product: About 10% of glucose is shunted into this pathway to generate NADPH (Nicotinamide Adenine Dinucleotide Phosphate).
- The Mechanism of Protection: Hemoglobin continuously generates highly toxic Reactive Oxygen Species (ROS), like Hydrogen Peroxide (H2O2). The RBC defends itself using an antioxidant protein called Glutathione (GSH). The enzyme Glutathione Peroxidase uses GSH to neutralize the dangerous H2O2 into harmless water. However, this process "uses up" the Glutathione, oxidizing it into GSSG. The NADPH generated by the HMP shunt is strictly used by the enzyme Glutathione Reductase to recycle the GSSG back into functional, active GSH.
Clinical Correlate: G6PD Deficiency
Glucose-6-Phosphate Dehydrogenase (G6PD) is the rate-limiting enzyme that starts the HMP Shunt. It is one of the most common genetic enzyme deficiencies worldwide. Patients with G6PD deficiency cannot produce enough NADPH.
Under normal conditions, they are fine. But if they are exposed to massive oxidative stress—such as eating Fava Beans, taking Sulfa antibiotics, using specific Antimalarial drugs (Primaquine), or fighting a severe bacterial infection—the generated H2O2 is not neutralized. The toxic ROS immediately destroy the hemoglobin, precipitating it into hard, destructive chunks called Heinz Bodies. As these RBCs pass through the spleen, macrophages take a literal bite out of the membrane to remove the Heinz body (creating Bite Cells), leading to massive, rapid hemolytic anemia.
3. The Rapoport-Luebering Shunt (2,3-Bisphosphoglycerate Pathway)
This is a unique metabolic side-branch of glycolysis found almost exclusively in erythrocytes.
- The Purpose: Instead of proceeding down standard glycolysis to make ATP, an enzyme called Bisphosphoglycerate mutase converts an intermediate into 2,3-Bisphosphoglycerate (2,3-BPG) (also historically called 2,3-DPG).
- The Mechanism: 2,3-BPG acts as a powerful allosteric modulator. It physically wedges itself into the center of the deoxygenated hemoglobin molecule. By binding there, it forces the hemoglobin to lock into the rigid "T-State", vastly decreasing the hemoglobin's affinity for oxygen.
- Clinical Significance: This forces the RBC to drop more oxygen into the tissues. If a person climbs a high mountain (hypoxia) or suffers from chronic lung disease (COPD), their RBCs massively ramp up the Rapoport-Luebering shunt to produce excessive 2,3-BPG, ensuring their starving tissues get maximum oxygen delivery. (This physically causes a "Right Shift" on the oxygen-hemoglobin dissociation curve).
4. The Methemoglobin Reductase Pathway
Oxygen naturally oxidizes the functional Ferrous iron (Fe2+) in hemoglobin into non-functional Ferric iron (Fe3+) at a slow, continuous rate of about 3% per day. This useless form is called Methemoglobin.
- The Defense: The RBC utilizes the enzyme Methemoglobin Reductase (also called Cytochrome b5 reductase). This enzyme uses NADH (harvested from standard glycolysis) to efficiently reduce the Ferric iron (Fe3+) straight back into functional Ferrous iron (Fe2+).
- Clinical Correlate: If an individual is exposed to excessive oxidizing toxins (like nitrites, local anesthetics like benzocaine, or specific antibiotics), the pathway is overwhelmed. The patient develops Methemoglobinemia. Their blood turns a thick, dark chocolate-brown color, and they exhibit profound "chocolate cyanosis" (blue/gray skin) because their blood can no longer carry oxygen. The emergency antidote is an IV infusion of Methylene Blue, which artificially accelerates the reductase enzyme to save the patient.
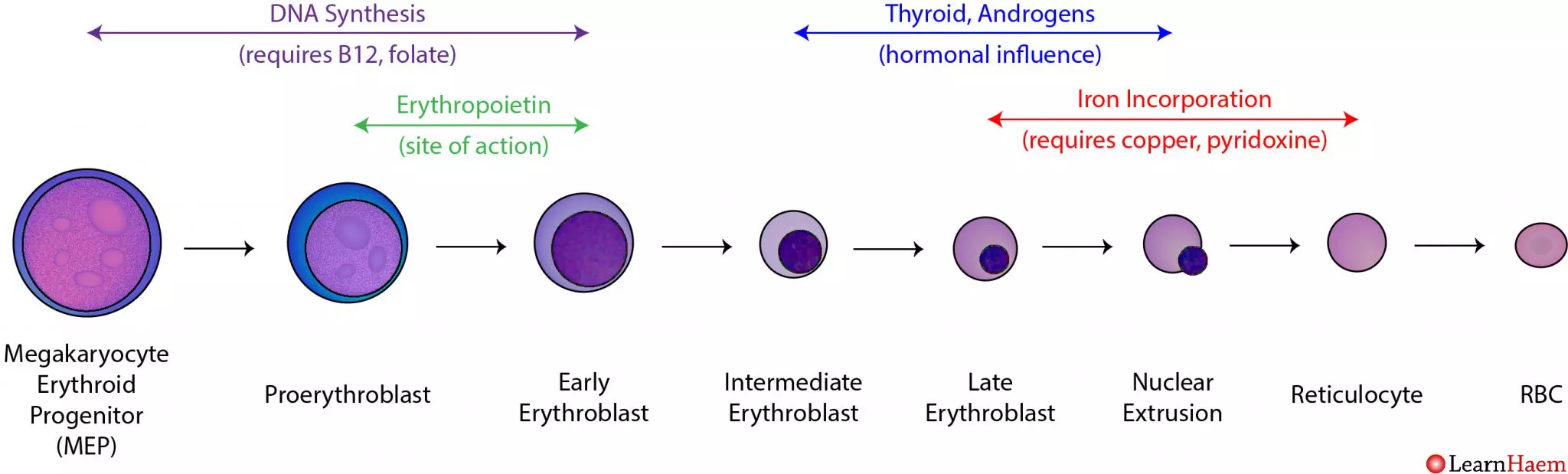
Section V: Erythropoiesis: The Birth of the Red Blood Cell
The lifespan of an RBC is short. To compensate for the loss of millions of cells per second, the body utilizes Erythropoiesis—the highly orchestrated, dynamic production of new red blood cells originating in the red bone marrow.
1. The Hypoxic Stimulus and Erythropoietin (EPO)
The bone marrow does not guess how many RBCs to make; it waits for a precise hormonal order.
- The Sensor: The peritubular interstitial cells of the Kidneys are incredibly sensitive to oxygen tension. If blood oxygen levels drop (due to high altitude, blood loss, or pulmonary disease), the kidneys detect the hypoxia.
- The Hormone: In response to hypoxia, the kidneys synthesize and secrete massive amounts of the glycoprotein hormone Erythropoietin (EPO) into the bloodstream.
- The Target: EPO travels directly to the red bone marrow and binds to specific receptors on committed hematopoietic stem cells, slamming the accelerator on cellular proliferation, accelerating maturation, and triggering hemoglobin synthesis.
Chronic Kidney Disease & Anemia
Patients suffering from end-stage renal disease (kidney failure) universally develop profound, chronic anemia. Why? Because their destroyed, fibrotic kidneys can no longer produce or secrete Erythropoietin. Without EPO, the bone marrow simply halts RBC production. Modern medicine treats this by injecting these patients with synthetic recombinant human Erythropoietin (rHuEPO) to forcefully restart the bone marrow.
2. The Sequential Stages of Erythropoiesis
The transformation from a generic stem cell to a highly specialized anucleated disc takes about 5 to 7 days, following an exact lineage:
- Hematopoietic Stem Cell (HSC): The multipotent granddaddy of all blood cells.
- Common Myeloid Progenitor (CMP): The cell commits to the myeloid line (excluding lymphocytes).
- Proerythroblast (Pronormoblast): The first committed, recognizable red cell precursor. It is massive, with a huge nucleus and dark blue (basophilic) cytoplasm packed with millions of ribosomes preparing to build protein.
- Basophilic Erythroblast: Rapid cellular division occurs. The nucleoli disappear.
- Polychromatic Erythroblast: The critical turning point. The cell begins actively synthesizing large amounts of red-staining Hemoglobin. The mixture of blue ribosomes and red hemoglobin causes the cytoplasm to stain a murky purple/gray (polychromatic).
- Orthochromatic Erythroblast (Normoblast): The cell is now fully packed with hemoglobin, staining a vibrant pink (eosinophilic). The nucleus ceases all function, condensing into a tight, dark, dead mass (pyknosis) before being forcefully ejected from the cell.
- Reticulocyte: The cell is now anucleated but still contains a residual, web-like net (reticulum) of ribosomal RNA. Reticulocytes are released from the bone marrow into the peripheral bloodstream. They circulate for exactly 1 to 2 days before the spleen plucks out the remaining RNA, finalizing their maturation.
Clinical Note: Measuring the blood Reticulocyte Count provides a direct, real-time window into bone marrow function. A high count means the marrow is working overtime (e.g., recovering from bleeding); a low count means the marrow is failing. - Mature Erythrocyte: The final, perfect biconcave disc ready for 120 days of service.
3. Absolute Nutritional Requirements
Erythropoiesis demands extreme amounts of raw building materials.
- Iron: The non-negotiable core of the heme group. It is absorbed in the duodenum, bound to the transport protein Transferrin in the blood, and delivered to the marrow. Excess is stored as Ferritin in the liver. A lack of iron results in Iron Deficiency Anemia (small, pale, empty RBCs).
- Vitamin B12 (Cobalamin) and Folate (Folic Acid): These two vitamins are absolutely vital for rapid DNA synthesis and cellular division. If either is missing, the DNA cannot replicate fast enough to divide. The cell cytoplasm continues to grow and fill with hemoglobin, but the nucleus lags behind (nuclear-cytoplasmic asynchrony). The result is the production of massive, fragile, dysfunctional red blood cells—a condition known as Megaloblastic Anemia (or Pernicious Anemia if driven by an autoimmune lack of Intrinsic Factor needed for B12 absorption).
- Amino Acids: Massive amounts of dietary protein are required to synthesize the millions of globin polypeptide chains.
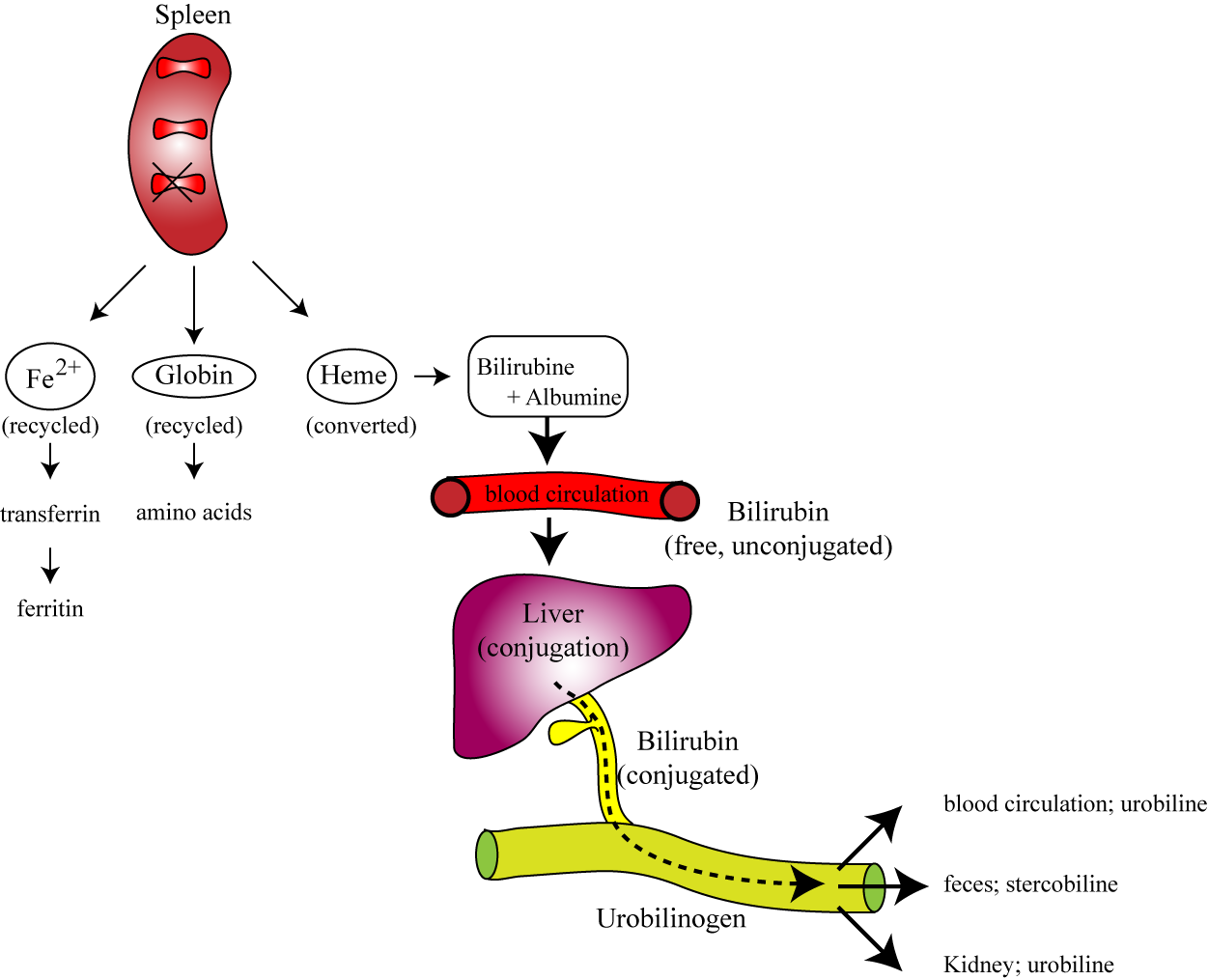
Section VI: Erythrocyte Senescence and Destruction
After a grueling 120-day journey, covering over 300 miles of vascular pathways, the RBC reaches the end of its life (senescence). Its enzymes fail, ATP is depleted, and the spectrin membrane becomes dangerously stiff, rigid, and fragile.
1. The Role of the Reticuloendothelial System (RES)
The vast majority (90%) of RBC destruction occurs smoothly and silently via Extravascular Hemolysis. The spleen acts as the ultimate quality-control filter. Old, rigid RBCs cannot squeeze through the tiny, hostile sinusoidal slits of the splenic red pulp. They become trapped. Waiting resident macrophages immediately recognize the damaged membrane proteins and ruthlessly phagocytize (devour) the aged RBCs. (The Kupffer cells of the liver and bone marrow macrophages assist in this process).
2. The Biochemical Breakdown and Recycling of Hemoglobin
Nothing goes to waste. The macrophage acts as a recycling center:
- Globin Chains: The massive protein structures are brutally catabolized by proteases into their individual constituent amino acids. These amino acids are dumped back into the blood plasma to be reused for general cellular protein synthesis or new erythropoiesis.
- The Heme Group: The heme ring requires delicate dismantling:
- Iron Extraction: The valuable Iron (Fe2+) is meticulously salvaged from the center of the ring. It is pushed out of the macrophage, binds to Transferrin in the blood, and is securely transported back to the bone marrow to build new hemoglobin, or stored safely as Ferritin.
- Porphyrin Ring Degradation: The empty organic ring is toxic and must be removed. The macrophage enzyme Heme Oxygenase rips the ring open, creating a green pigment called Biliverdin (with the release of a tiny amount of Carbon Monoxide gas).
- Unconjugated Bilirubin: Biliverdin is rapidly reduced by Biliverdin Reductase into a yellow/orange toxic waste pigment called Unconjugated (Indirect) Bilirubin. Because this molecule is highly lipid-soluble and utterly water-insoluble, it must bind tightly to the plasma protein Albumin to safely travel through the bloodstream to the liver.
- Hepatic Conjugation: Inside the liver hepatocytes, the enzyme UDP-glucuronosyltransferase (UGT) forces glucuronic acid onto the bilirubin. This transforms it into Conjugated (Direct) Bilirubin, making it highly water-soluble. The liver excretes this safe, water-soluble conjugated bilirubin into the bile duct, draining it into the small intestines to help emulsify dietary fats.
- Intestinal Excretion: In the large intestine, normal gut flora (bacteria) metabolize the conjugated bilirubin into Urobilinogen. A tiny fraction is reabsorbed into the blood and filtered by the kidneys, oxidizing into Urobilin (giving urine its characteristic yellow color). The vast majority remains in the gut, undergoing oxidation into Stercobilin, which is exclusively responsible for giving human feces its characteristic brown color.
Clinical Pathology: Jaundice (Icterus)
If any step in the RBC destruction and bilirubin clearance pathway fails, bilirubin accumulates massively in the blood (hyperbilirubinemia). Because bilirubin is yellow, it deposits in the skin and the sclera (white parts) of the eyes, causing intense yellowing known as Jaundice. We classify this diagnostically:
- Pre-hepatic Jaundice: Massive RBC destruction (e.g., Sickle cell crisis, Malaria, G6PD attack). The spleen crushes so many RBCs that it creates more unconjugated bilirubin than the liver can possibly handle.
- Hepatic Jaundice: The liver itself is sick (e.g., Viral Hepatitis, Cirrhosis) and simply lacks the cellular machinery to conjugate the normal daily load of bilirubin.
- Post-hepatic (Obstructive) Jaundice: The liver works perfectly and conjugates the bilirubin, but a physical blockage (e.g., a massive gallstone blocking the bile duct or pancreatic cancer) prevents the bile from draining into the intestines. The conjugated bilirubin backs up into the blood, causing dark urine and remarkably pale, clay-colored feces (because no stercobilin is made).
Section VII: List of References
- Hall, J. E., & Guyton, A. C. (2015). Guyton and Hall Textbook of Medical Physiology (13th ed.). Philadelphia, PA: Elsevier Saunders. (Chapters detailing Erythrocytes, Anemia, and Polycythemia).
- Kumar, V., Abbas, A. K., & Aster, J. C. (2020). Robbins & Cotran Pathologic Basis of Disease (10th ed.). Philadelphia, PA: Elsevier. (Sections on Hemodynamic Disorders, Hemoglobinopathies, and Jaundice).
- Hoffbrand, A. V., & Steensma, D. P. (2019). Hoffbrand's Essential Haematology (8th ed.). Wiley-Blackwell. (Comprehensive chapters on Erythropoiesis, RBC metabolism, and Hemolytic Anemias).
- Ferrier, D. R. (2017). Lippincott Illustrated Reviews: Biochemistry (7th ed.). Wolters Kluwer. (In-depth analysis of the Pentose Phosphate Pathway, Glycolysis, and Hemoglobin Structure/Function).
- Mescher, A. L. (2018). Junqueira's Basic Histology: Text and Atlas (15th ed.). McGraw-Hill Education. (Ultrastructural details of the erythrocyte cytoskeleton and bone marrow architecture).
Red Blood Cells Quiz
Test your knowledge with these 35 questions.
Red Blood Cells Quiz
Question 1/35
Quiz Complete!
Here are your results, .
Your Score
33/35
94%
Red Blood Cells (Erythrocytes) Physiology Read More »
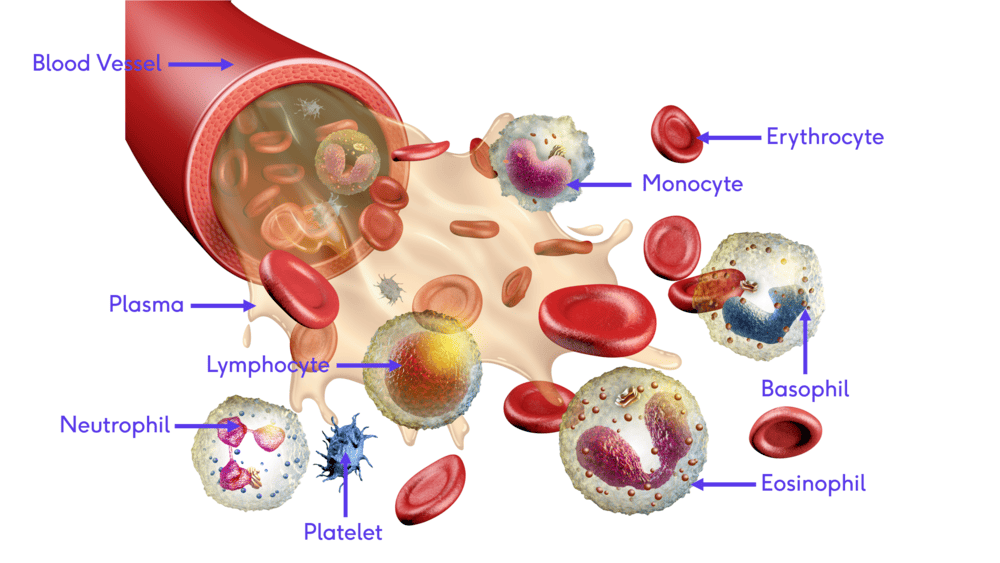
Blood Physiology: Introduction
Introduction to Blood
Blood is often described as a unique connective tissue, though it differs significantly from other connective tissues like bone or cartilage. Its uniqueness stems from its cellular components being suspended in a liquid extracellular matrix (plasma) rather than being anchored to solid fibers. This fluidity is crucial for its transport functions.
It is the only fluid tissue in the body, continuously circulating within the closed system of the cardiovascular system (heart, blood vessels). It is a complex, viscous fluid that accounts for approximately 8% of total body weight in an average adult (e.g., about 5-6 liters in males, 4-5 liters in females).
Origin: All blood cells originate from hematopoietic stem cells in the red bone marrow.
Why is it essential for life?
- Blood serves as the body's primary transport and communication medium, ensuring that all cells receive necessary resources and waste products are efficiently removed. Without its continuous circulation, cells would rapidly cease to function due to lack of oxygen and nutrients, and the accumulation of toxic metabolic byproducts.
- It acts as a dynamic internal environment, constantly adapting to the body's changing needs and maintaining homeostasis (the stable internal conditions required for survival).
Overview of Major Roles of Blood
1. Distribution/Transportation
Blood acts as the delivery system for the body:
- Respiratory Gases:
- Carries oxygen from the lungs (where it's loaded onto hemoglobin in red blood cells) to all body tissues and cells for cellular respiration.
- Transports carbon dioxide, a waste product of cellular respiration, from body cells back to the lungs for exhalation (dissolved in plasma, bound to hemoglobin, or as bicarbonate ions).
- Nutrients: Delivers absorbed nutrients (e.g., monosaccharides like glucose, amino acids, fatty acids, glycerol, vitamins, minerals) from the digestive tract to the liver first, and then to all body cells for energy, growth, and repair.
- Hormones: Acts as the "circulatory highway" for endocrine hormones, transporting them from their sites of production (endocrine glands) to their specific target organs or cells throughout the body, regulating diverse physiological processes.
- Metabolic Wastes: Collects and transports metabolic waste products, such as urea (from protein metabolism) and uric acid (from nucleic acid metabolism) to the kidneys for excretion in urine, and lactic acid (from anaerobic respiration) to the liver for conversion.
2. Regulation
Blood plays a pivotal role in maintaining the stability of the interstitial fluid (homeostasis):
- Body Temperature: Blood possesses a high heat capacity due to its water content. It absorbs heat generated by metabolically active tissues (e.g., muscles) and distributes it throughout the body. By regulating blood flow to the skin, it can either dissipate excess heat (vasodilation) or conserve heat (vasoconstriction) to maintain a stable core body temperature.
- pH Levels: Crucial for maintaining the extremely narrow and vital physiological pH range of 7.35-7.45. It achieves this through various buffer systems present in plasma proteins and within red blood cells (e.g., bicarbonate buffer system, phosphate buffer system, protein buffer system). These buffers can accept or donate hydrogen ions to resist drastic changes in acidity or alkalinity.
- Fluid Volume and Blood Pressure: Blood plasma proteins, particularly albumin, exert significant osmotic pressure (colloid osmotic pressure). This pressure draws water from the interstitial fluid back into the capillaries, maintaining proper fluid volume within the circulatory system and helping to prevent edema (swelling of tissues). Maintaining adequate blood volume is directly linked to maintaining sufficient blood pressure for tissue perfusion.
-
Electrolyte Balance: Transports various electrolytes (
Na+,K+,Ca2+,Cl-,HCO3-) which are vital for nerve impulse transmission, muscle contraction, and fluid balance.
3. Protection
Blood provides defense mechanisms against blood loss and foreign invaders:
- Prevention of Blood Loss (Hemostasis): Initiates a rapid and efficient series of events when a blood vessel is damaged. This process, called hemostasis, involves the aggregation of platelets (thrombocytes) and the activation of clotting factors (plasma proteins) to form a fibrin clot, sealing the injured vessel and preventing excessive hemorrhage.
- Prevention of Infection:
- Leukocytes (White Blood Cells): Are the mobile units of the immune system. They identify and destroy pathogens (bacteria, viruses, fungi, parasites) and remove damaged or abnormal cells (e.g., cancer cells, dead cells). Different types of leukocytes have specialized roles in this defense.
- Antibodies: Specific proteins (immunoglobulins) produced by certain lymphocytes that target and neutralize specific pathogens or toxins.
- Complement Proteins: A group of plasma proteins that, when activated, can lyse microorganisms, enhance phagocytosis, and contribute to inflammation.
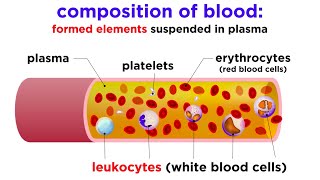
Physical Characteristics
Appearance & Texture
- Oxygen-rich blood: (typically arterial) is a bright, scarlet red. This vibrant color is due to hemoglobin picking up oxygen in the lungs (oxyhemoglobin).
- Oxygen-poor blood: (typically venous) is a darker, duller red, sometimes described as brick-red or maroon. This is because hemoglobin has released its oxygen (deoxyhemoglobin). Note: Venous blood is never blue, despite how veins appear through the skin.
Blood is about 5 times more viscous (thicker/stickier) than water, primarily due to RBCs and plasma proteins.
Properties
Slightly alkaline (basic), maintained tightly between 7.35 and 7.45.
- pH < 7.35 = Acidosis
- pH > 7.45 = Alkalosis
Circulates at ~38°C (100.4°F), slightly higher than body temperature, to absorb and distribute metabolic heat.
Metallic taste (iron content) and faint characteristic odor.
Volume: The average adult has approximately 5-6 liters (1.5 gallons), constituting 7-8% of total body weight.
Clinical Significance: Significant deviations (hemorrhage, fluid overload) severely compromise tissue perfusion.
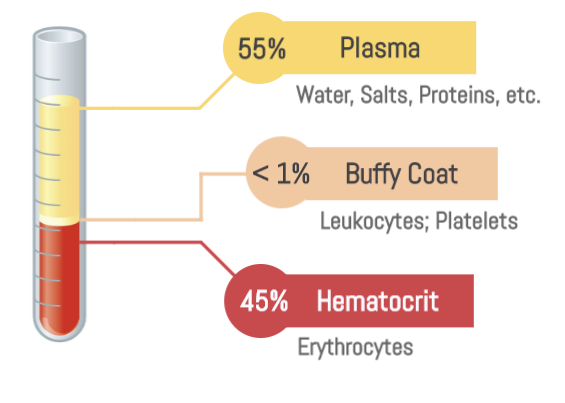
Composition of Blood: The Two Major Components
When a sample of blood is collected and centrifuged (spun at high speed), its components separate into distinct layers due to differences in density. This separation reveals two main components:
55%
45%
1. Plasma (Liquid Matrix)
Constitutes ~55% of total volume.
- Least dense component; forms top, yellowish-straw colored layer.
- A sticky, non-living fluid matrix.
- (Detailed composition covered in Objective 1.3)
2. Formed Elements (Cellular)
Constitutes ~45% of total volume (Hematocrit).
Normal Hematocrit: Males 42-52%, Females 37-47%.
-
Erythrocytes (RBCs):
Most numerous (99.9%). Dense red mass at the bottom. Responsible for O2 transport. -
The "Buffy Coat" (Top of formed elements):
Thin, whitish layer between plasma and RBCs containing:- Leukocytes (WBCs): Critical for immune defense.
- Thrombocytes (Platelets): Fragments involved in clotting.

Composition and Functions of Blood Plasma
Plasma is the non-living fluid matrix of blood, accounting for approximately 55% of total blood volume. It is a complex mixture, predominantly water, with a vast array of dissolved solutes, many of which are vital for maintaining homeostasis.
Composition of Blood Plasma
1. Water (approx. 90% by weight)
This is the major component of plasma, serving as the solvent for all other plasma constituents.
Function:
- Acts as the medium for dissolving and suspending solutes.
- Excellent heat absorber and distributor, contributing to thermoregulation.
- Provides the fluidity necessary for blood circulation.
2. Plasma Proteins (approx. 8% by weight)
These are the most abundant solutes in plasma by weight and are almost entirely produced by the liver (with the exception of gamma globulins/antibodies). They are not taken up by cells to be used as metabolic fuels or nutrients (unlike other plasma solutes), but rather remain in the blood.
Key Functions (collectively): Contribute to osmotic pressure, act as buffers, transport substances, and play roles in blood clotting and immunity.
Albumin
Most abundant plasma protein.
Main contributor to plasma osmotic pressure: It acts like a sponge, drawing water from the interstitial fluid into the bloodstream, thereby maintaining blood volume and blood pressure.
Important buffer: Helps to maintain blood pH.
Carrier protein: Transports various substances in the blood, including certain hormones (e.g., thyroid hormones, steroid hormones), fatty acids, and some drugs.
Globulins
A diverse group of proteins.
- Transport proteins that bind to and transport lipids (forming lipoproteins), metal ions (e.g., transferrin for iron), and fat-soluble vitamins.
- Some are involved in immune responses.
- Also known as antibodies or immunoglobulins.
- Produced by plasma cells (derived from B lymphocytes), not the liver.
- Function: Critical components of the immune system, recognizing and attacking pathogens.
Fibrinogen
A large plasma protein produced by the liver.
Function: Key component of the blood clotting cascade. It is converted into fibrin, which forms the meshwork of a blood clot.
Other Plasma Proteins: Includes enzymes, complement proteins (involved in immunity), and various regulatory proteins.
Other Solutes
3. Nutrients (approx. 1%)
Substances absorbed from the digestive tract and transported to body cells.
Examples: Glucose (blood sugar), amino acids, fatty acids, glycerol, vitamins, cholesterol.
4. Electrolytes (Ions - approx. 1%)
Inorganic salts, primarily Na+, Cl-, K+, Ca2+, Mg2+, HCO3-, HPO42-, and SO42-.
Most abundant plasma solutes by number.
- Maintain plasma osmotic pressure.
- Crucial for buffering blood pH.
- Essential for nerve impulse transmission, muscle contraction, and enzyme activity.
- Electrolyte balance is vital for body fluid distribution.
5. Gases
Dissolved O2, CO2, and N2.
Function: Transport of respiratory gases. (Note: Most are transported by RBCs, but a small amount dissolves in plasma).
6. Hormones
Steroid and protein-based hormones transported to target cells to regulate physiology.
7. Waste Products
Byproducts of metabolism transported to kidneys/lungs/liver.
Examples: Urea, uric acid, creatinine, ammonium salts.
Functions of Blood Plasma (Summary)
- Transport: Serves as the primary medium for transporting nutrients, gases, hormones, metabolic wastes, and drugs throughout the body.
-
Regulation:
- Osmotic Pressure & Fluid Balance: Plasma proteins, especially albumin, maintain the body's fluid volume and osmotic pressure.
- pH Balance: Plasma proteins and bicarbonate ions act as buffers.
- Temperature Regulation: Water content helps distribute and dissipate heat.
- Protection: Contains antibodies and complement proteins for immunity, and clotting factors (like fibrinogen) to prevent blood loss.
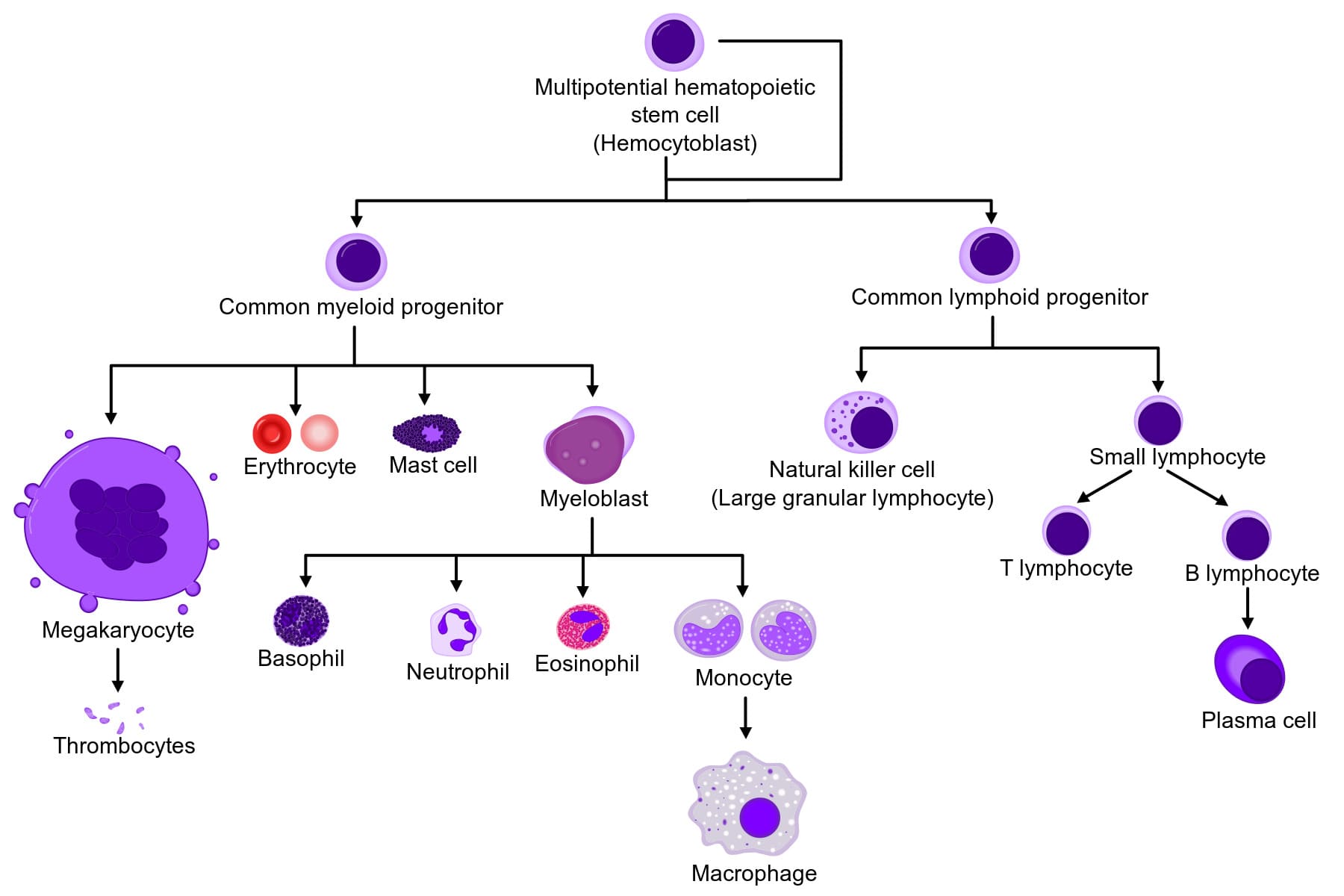
Haematopoiesis: Formation of Blood Cells
Haematopoiesis (Gr. haima = blood; poiesis = to make) is the process of generating all of the cellular components of blood from hematopoietic stem cells (HSCs).
This includes the formation of:
- Erythropoiesis: Production of Erythrocytes (red blood cells).
- Leukopoiesis: Production of Leukocytes (white blood cells).
- Thrombopoiesis: Production of Thrombocytes (platelets).
Significance
1. Maintenance of Blood Cell Homeostasis:
Blood cells have finite lifespans (e.g., RBCs ~120 days, platelets ~10 days, neutrophils ~hours to days). Hematopoiesis ensures that old or damaged cells are constantly replaced by new ones, maintaining stable numbers of each cell type.
2. Response to Physiological Demands:
The rate of hematopoiesis can be dramatically increased in response to specific physiological needs, such as:
- Anemia: Increased erythropoiesis to compensate for low red blood cell count or oxygen-carrying capacity.
- Infection: Increased leukopoiesis (especially granulopoiesis) to combat pathogens.
- Hemorrhage: Increased production of red blood cells and platelets to replace lost blood volume and ensure clotting.
3. Repair and Regeneration: Provides the cells necessary for tissue repair, immune surveillance, and defense against injury and disease.
4. Adaptation: Allows the body to adapt to changes in environmental conditions (e.g., higher altitude, requiring more RBCs).
Sites of Hematopoiesis
1. Embryonic Hematopoiesis
- Yolk Sac: Begins very early in embryonic development (around 3rd week of gestation). Primitive red blood cells are formed here.
- Aorta-Gonad-Mesonephros (AGM) region: A crucial site for the emergence and expansion of definitive HSCs.
- Liver: Becomes the primary hematopoietic organ during the second trimester of fetal development.
- Spleen: Also contributes significantly to hematopoiesis during fetal life.
2. Fetal Hematopoiesis
- Liver and Spleen: Are the dominant sites from the second trimester until near birth.
- Bone Marrow: Begins to take over as the primary site during the late fetal period.
3. Adult Hematopoiesis
Red Bone Marrow:
After birth and throughout adulthood, red bone marrow is the sole site of normal hematopoiesis.
- Location: Found primarily in the axial skeleton (skull, vertebrae, ribs, sternum), pelvic girdle, and the epiphyses (ends) of the humerus and femur.
- Composition: Composed of a vascular compartment and a hematopoietic compartment, including hematopoietic stem cells, progenitor cells, developing blood cells, and a stroma (supportive tissue including reticular cells, adipocytes, macrophages).
Yellow Bone Marrow:
In adults, much of the red bone marrow is replaced by yellow bone marrow (composed mainly of fat cells), which is generally quiescent in hematopoiesis but can convert back to red marrow in cases of extreme demand (e.g., severe hemorrhage).
Extramedullary Hematopoiesis: In certain pathological conditions (e.g., severe bone marrow failure, chronic myeloproliferative disorders), the liver and spleen can reactivate their fetal hematopoietic capacity, leading to blood cell production outside the bone marrow.
Role of Hematopoietic Stem Cells (HSCs)
At the pinnacle of the hematopoietic system are the Hematopoietic Stem Cells (HSCs), the remarkable cells responsible for generating all mature blood cells. Understanding HSCs is fundamental to comprehending blood cell formation.
Characteristics of HSCs
1. Pluripotency (Multipotency)
HSCs are pluripotent (more accurately, multipotent). They have the unique ability to differentiate into all types of blood cells (RBCs, WBCs, Platelets). They cannot, however, differentiate into cells of other tissues (like neurons), which is why they are not considered totipotent.
2. Self-Renewal
HSCs undergo asymmetric cell division: one daughter cell remains an undifferentiated stem cell (replenishing the pool) and the other commits to differentiation. This ensures a lifelong supply. Without this, the stem cell pool would eventually deplete.
3. Quiescence
Most HSCs in the marrow exist in a relatively quiescent (resting) state, dividing infrequently to protect from DNA damage and exhaustion. However, they can be rapidly activated in response to stress (infection, hemorrhage).
4. Rare Population
HSCs are an extremely rare population of cells within the bone marrow, estimated to be less than 0.01% of all bone marrow cells.
Differentiation Pathways: The "Hematopoietic Tree"
HSCs don't directly differentiate into mature blood cells. Instead, they undergo a series of commitment steps, forming progenitor cells that have more restricted differentiation potential.
Commitment to Lineage
Upon commitment, an HSC differentiates into one of two major progenitor cell types:
Common Myeloid Progenitor (CMP)
Gives rise to most cells involved in innate immunity and oxygen transport.
- Erythrocytes (RBCs): via Erythropoiesis.
- Megakaryocytes: leading to Platelets via Thrombopoiesis.
- Granulocytes: Neutrophils, Eosinophils, Basophils.
- Monocytes: Mature into macrophages in tissues.
- (Some also include mast cells from this lineage).
Common Lymphoid Progenitor (CLP)
Gives rise to cells primarily involved in adaptive immunity.
- B Lymphocytes: Mature into plasma cells and produce antibodies.
- T Lymphocytes: Involved in cell-mediated immunity.
- Natural Killer (NK) cells: Important components of innate immunity.
Significance of HSCs
- Lifelong Blood Production: Crucial for maintaining the continuous supply of all blood cell types throughout an individual's life.
- Therapeutic Potential: HSCs are the basis for bone marrow transplantation (more accurately, hematopoietic stem cell transplantation), a life-saving procedure used to treat various blood cancers (leukemias, lymphomas), bone marrow failure syndromes (aplastic anemia), and certain genetic disorders.
Blood Physiology: Introduction
Test your knowledge with these 40 questions.
Blood Physiology Quiz
Question 1/40
Quiz Complete!
Here are your results, .
Your Score
38/40
95%
Blood Physiology: Introduction Read More »
Genetic Code & Chromosomes
Biochemistry: Genetic Code & Chromosomes
Test your knowledge with these 30 questions.
Genetic Code & Chromosomes Quiz
Question 1/30
Quiz Complete!
Here are your results, .
Your Score
27/30
90%
Genetic Code & Chromosomes Read More »
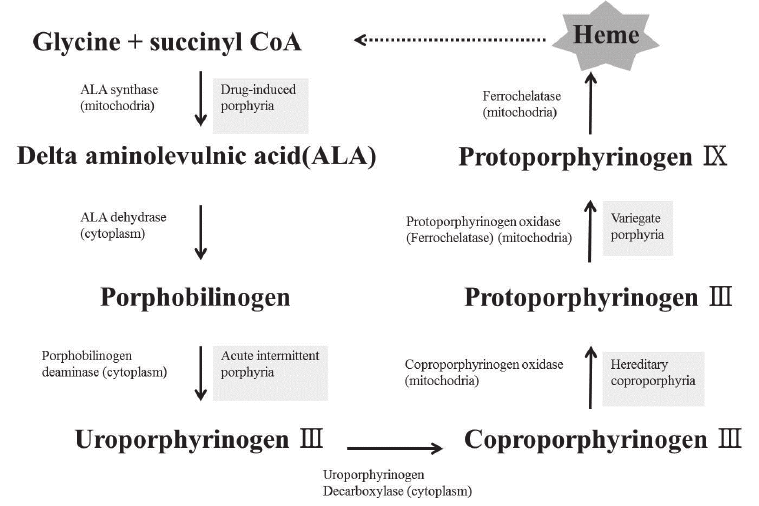
Heme Metabolism Pathway
Heme Metabolism: Biosynthesis
Heme is a vital molecule. It acts as a "prosthetic group" (a permanent helper) for proteins like Hemoglobin (oxygen transport), Myoglobin (oxygen storage), and Cytochromes (drug detoxification and electron transport).
1. Structure & Definitions
What is a Porphyrin?
Porphyrins are large, cyclic compounds made of 4 Pyrrole Rings linked together by methenyl bridges.
They are famous for binding metal ions.
Example: Magnesium in Chlorophyll (plants).
Example: Iron in Heme (humans).
The Side Chains
The properties of the porphyrin depend on which "decorations" (side chains) are attached to the rings:
- A: Acetate (Acetyl)
- P: Propionate (Propionyl)
- M: Methyl
- V: Vinyl
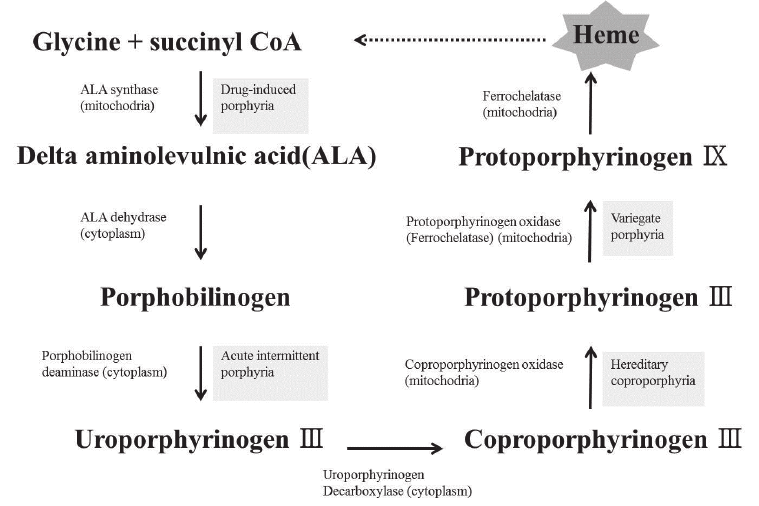
2. Steps of Heme Synthesis
This process is like a relay race. It starts in the Mitochondria, runs out to the Cytosol, and finishes back in the Mitochondria.
Step 1: Formation of ALA (The Rate-Limiting Step)
The Reaction:
Succinyl CoA (from TCA cycle) + Glycine → δ-Aminolevulinate (ALA) + CO₂
- Enzyme: ALA Synthase (ALAS).
- Coenzyme Required: Pyridoxal Phosphate (Vitamin B6).
- Significance: This is the Committed Step. Once this happens, the cell is committed to making Heme.
- ALAS-1: Found in the Liver (and all tissues).
- ALAS-2: Found in Bone Marrow (Erythroid cells).
Clinical Note: Mutation in ALAS-2 causes X-Linked Sideroblastic Anemia (Iron cannot be used, so it piles up).
Steps 2 to 5: Building the Ring in the Cytosol
Step 2: Formation of Porphobilinogen (PBG)
2 molecules of ALA condense to form 1 Ring (PBG).
- Enzyme: ALA Dehydratase (also called PBG Synthase).
- Requirement: This enzyme contains Zinc.
Result: ALA accumulates (Neurotoxic) causing brain damage and anemia.
Step 3: Formation of Hydroxymethylbilane (HMB)
4 molecules of PBG are linked together in a line (Linear Tetrapyrrole).
- Enzyme: HMB Synthase (PBG Deaminase).
Step 4: Ring Closure (Uroporphyrinogen III)
The linear chain is curled into a circle.
- Enzyme: Uroporphyrinogen III Synthase.
- Mechanism: It flips one of the rings to create an asymmetric "Type III" structure.
- Note: If this enzyme is missing, the ring closes spontaneously but incorrectly (Type I), which is useless to the body.
Step 5: Decarboxylation
Uroporphyrinogen III → Coproporphyrinogen III
- Enzyme: Uroporphyrinogen Decarboxylase.
- Action: Removes Carboxyl groups (CO₂). This makes the molecule less water-soluble (more hydrophobic) so it can re-enter the mitochondria.
Steps 6 to 9: The Final Touches
-
Step 6 & 7: Oxidation
Coproporphyrinogen III enters the mitochondria. It is oxidized to Protoporphyrinogen IX and then to Protoporphyrin IX.
Enzymes: Coproporphyrinogen Oxidase & Protoporphyrinogen Oxidase.
Key Detail: Step 8 creates double bonds, giving the molecule its red color. -
Step 9: Insertion of Iron (The Finale)
Protoporphyrin IX + Fe²⁺ (Ferrous) → HEME
- Enzyme: Ferrochelatase (Heme Synthase).
- Inhibitor: This enzyme is ALSO sensitive to Lead. Lead poisoning blocks the final insertion of iron.
3. Regulation of Heme Synthesis
The body carefully controls the first enzyme, ALA Synthase, to prevent overproduction.
Heme (the product) acts as a negative regulator.
- Repression: Heme stops the gene from making more ALA Synthase.
- Allosteric Inhibition: Hematin (Heme with Fe³⁺) binds directly to the enzyme to stop it.
Drugs like Barbiturates (sedatives) increase Heme synthesis.
- Barbiturates are metabolized by Cytochrome P450 in the liver.
- Cytochrome P450 contains Heme.
- Metabolizing the drug consumes the Heme.
- Free Heme levels drop.
- The "Brake" (Feedback Inhibition) is removed.
- ALA Synthase increases to replenish the lost Heme.
High concentrations of Glucose inhibit the induction of ALA Synthase.
Clinical Relevance: Giving glucose (IV sugar) is part of the treatment for acute attacks of Porphyria to try and slow down the pathway.
This is a Tuberculosis drug. It depletes Pyridoxal Phosphate (Vitamin B6).
Since Step 1 requires B6, INH can stop Heme synthesis and cause anemia.